create choropleth map using tmap’s elements and leverage its aesthetics
2. Introduction
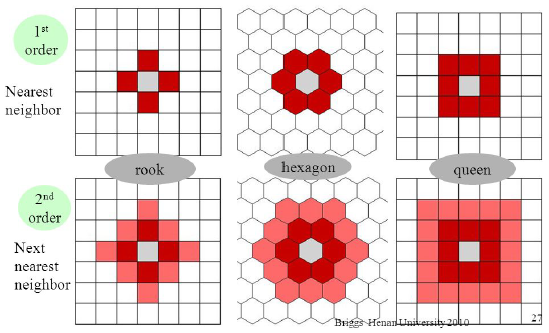
Spatial statistics integrate space and spatial relationships directly into their mathematics (area, distance, length, or proximity, for example). Typically, these spatial relationships are defined formally through values called spatial weights. Spatial weights are structured into a spatial weights matrix and stored as a spatial weights matrix file. Spatial weights are a way to define spatial neighbourhood. One practical use case can be - Are these two planning zones neighbours? They can be determined by either contiguity neighbours - rook / hexagon / queen or adjacency based neighbours - weight matrix
3. Glimpse of Steps
Some of the important steps performed in this study are as follows
importing geospatial data using appropriate function(s) of sf package,
importing csv file using appropriate function of readr package,
performing relational join using appropriate join function of dplyr package,
computing spatial weights using appropriate functions of spdep package, and
calculating spatially lagged variables using appropriate functions of spdep package.
4. Data
Following two data sets are used:
Hunan country boundary layer. This is a geospatial data set in ESRI shapefile format.
Hunan_2012.csv: This csv file contains selected Hunan’s local development indicators in 2012.
5. Deep Dive into Map Analysis
5.1 Installing libraries and Importing files
p_load function pf pacman package is used to install and load sf ,tidyverse and tmap packages into R environment. First, let us import Hunan shapefile into R using st_read() of sf package. The imported shapefile will be simple features Object of sf. Next, let us import Hunan_2012.csv into R by using read_csv() of readr package. The output is R dataframe class.
Rows: 88 Columns: 29
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): County, City
dbl (27): avg_wage, deposite, FAI, Gov_Rev, Gov_Exp, GDP, GDPPC, GIO, Loan, ...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
5.2 Data Wrangling
The code chunk below will be used to update the attribute table of hunan’s SpatialPolygonsDataFrame with the attribute fields of hunan2012 dataframe. This is performed by using left_join() of dplyr package.
hunan <-left_join(hunan,hunan2012)
Joining, by = "County"
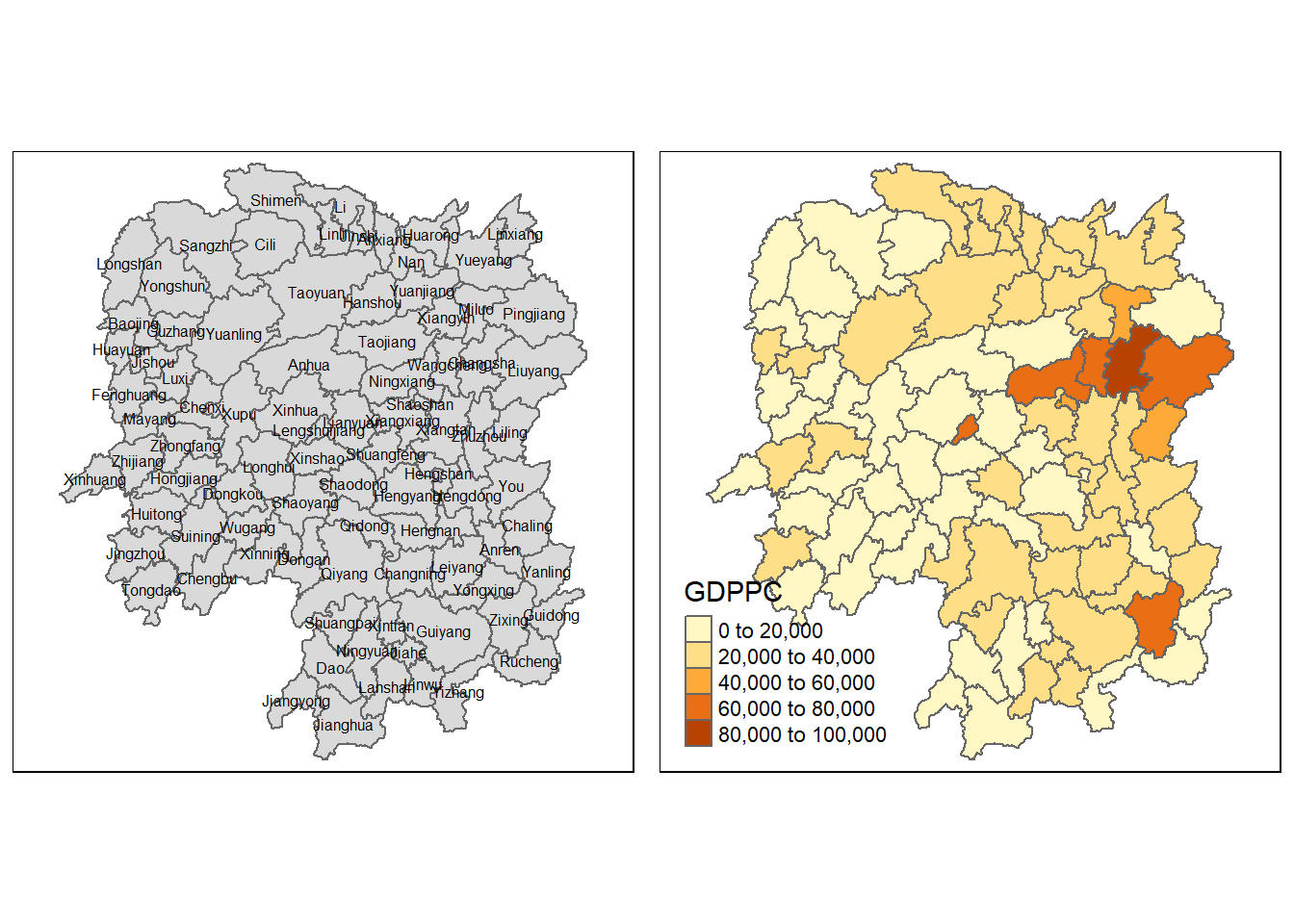
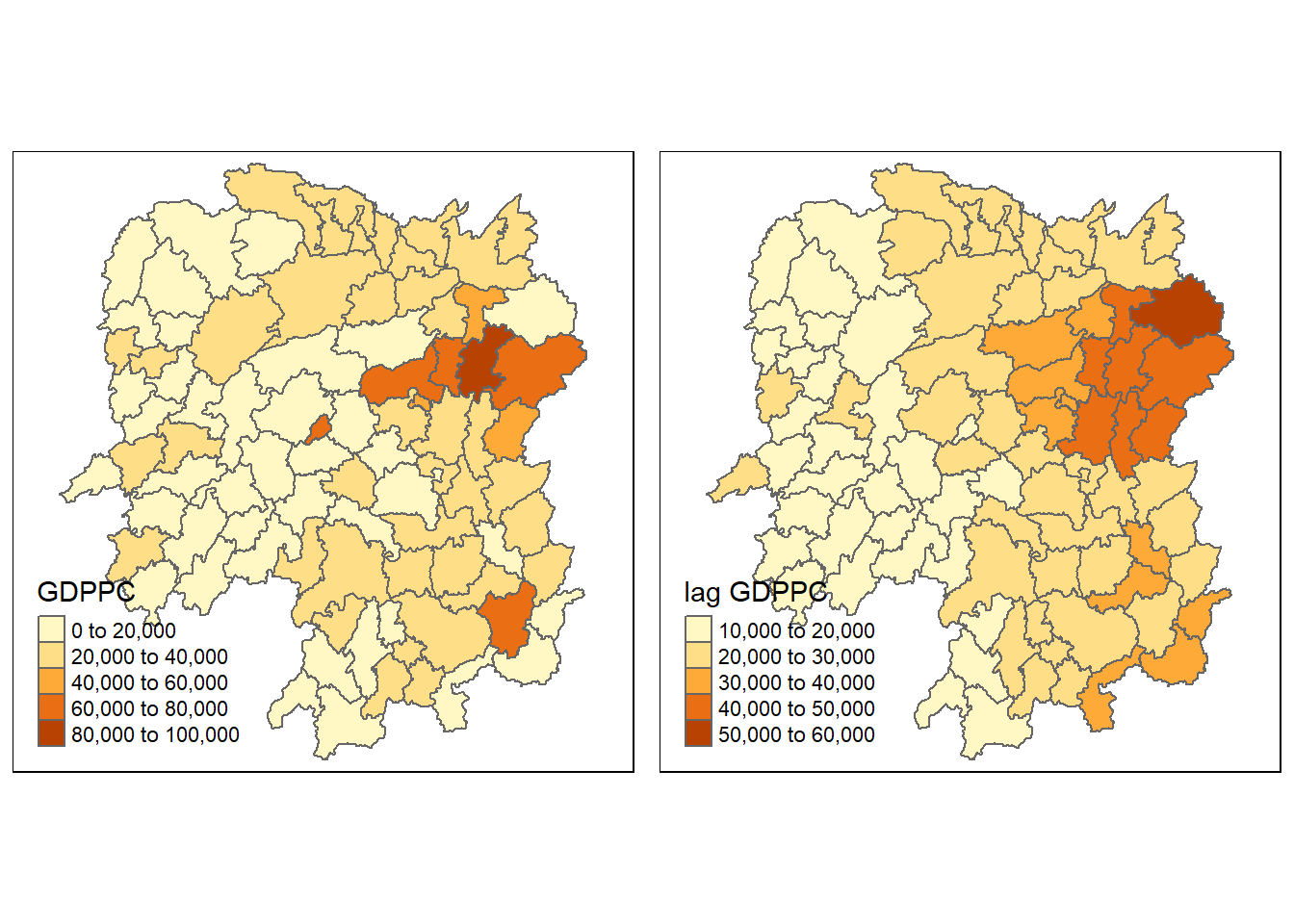
5.3 Visualising Regional Development Indicator
Now, we are going to prepare a basemap and a choropleth map showing the distribution of GDPPC 2012 by using qtm() of tmap package.
In this sub section, let u see how to use poly2nb() of spdep package to compute contiguity weight matrices for the study area. This function builds a neighbours list based on regions with contiguous boundaries.
5.4.1 Computing (QUEEN) contiguity based neighbours
The code chunk below is used to compute Queen contiguity weight matrix.
wm_q <-poly2nb(hunan, queen=TRUE)summary(wm_q)
Neighbour list object:
Number of regions: 88
Number of nonzero links: 448
Percentage nonzero weights: 5.785124
Average number of links: 5.090909
Link number distribution:
1 2 3 4 5 6 7 8 9 11
2 2 12 16 24 14 11 4 2 1
2 least connected regions:
30 65 with 1 link
1 most connected region:
85 with 11 links
The summary report above shows that there are 88 area units in Hunan. The most connected area unit has 11 neighbours. There are two area units with only one heighbours.
wm_q[[1]]
[1] 2 3 4 57 85
hunan$County[1]
[1] "Anxiang"
hunan$NAME_3[c(2,3,4,57,85)]
[1] "Hanshou" "Jinshi" "Li" "Nan" "Taoyuan"
nb1 <- wm_q[[1]]nb1 <- hunan$GDPPC[nb1]nb1
[1] 20981 34592 24473 21311 22879
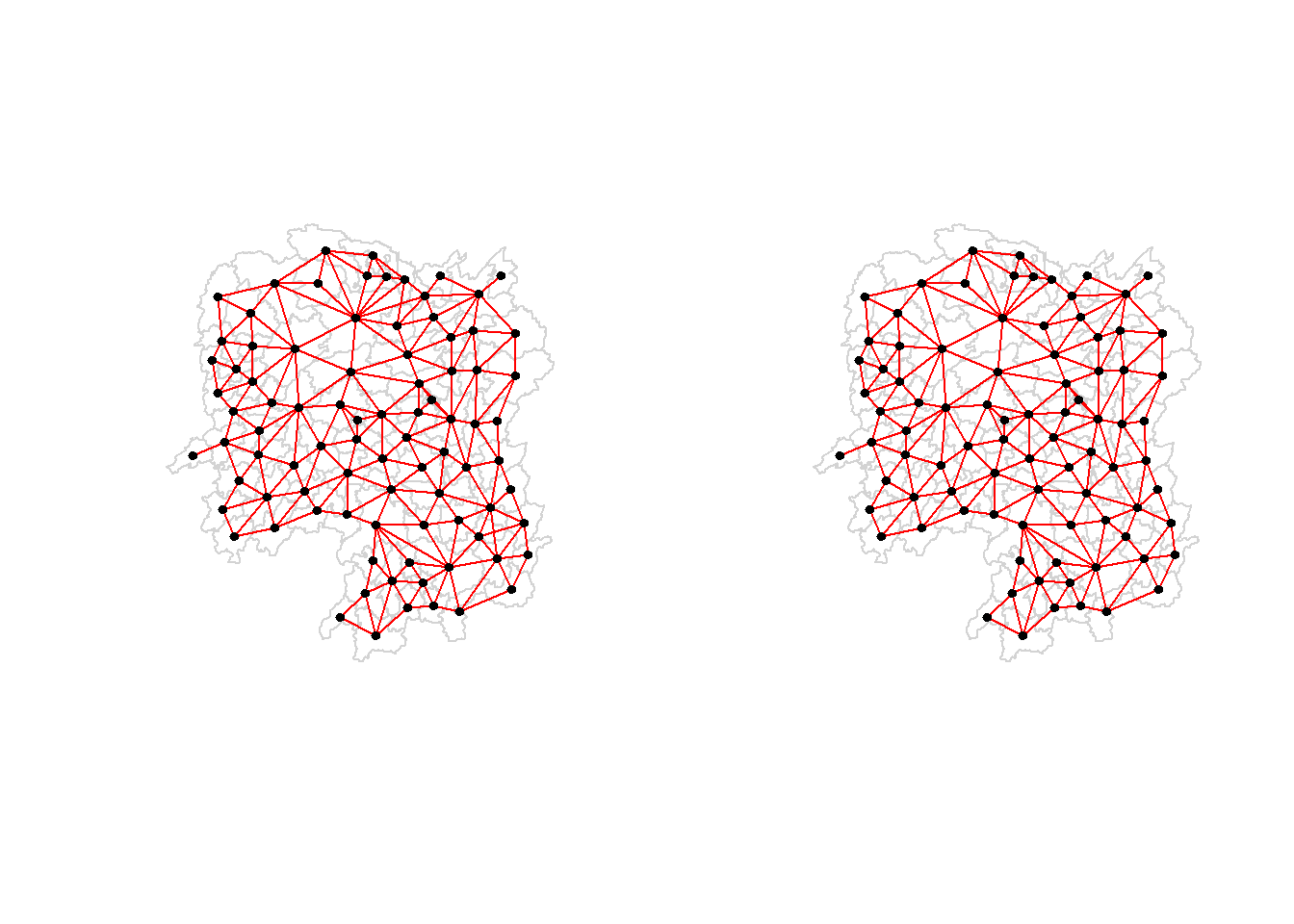
5.4.2 Creating (ROOK) contiguity based neighbours
The code chunk below is used to compute Rook contiguity weight matrix.
wm_r <-poly2nb(hunan, queen=FALSE)summary(wm_r)
Neighbour list object:
Number of regions: 88
Number of nonzero links: 440
Percentage nonzero weights: 5.681818
Average number of links: 5
Link number distribution:
1 2 3 4 5 6 7 8 9 10
2 2 12 20 21 14 11 3 2 1
2 least connected regions:
30 65 with 1 link
1 most connected region:
85 with 10 links
The summary report above shows that there are 88 area units in Hunan. The most connect area unit has 10 neighbours. There are two area units with only one heighbours.
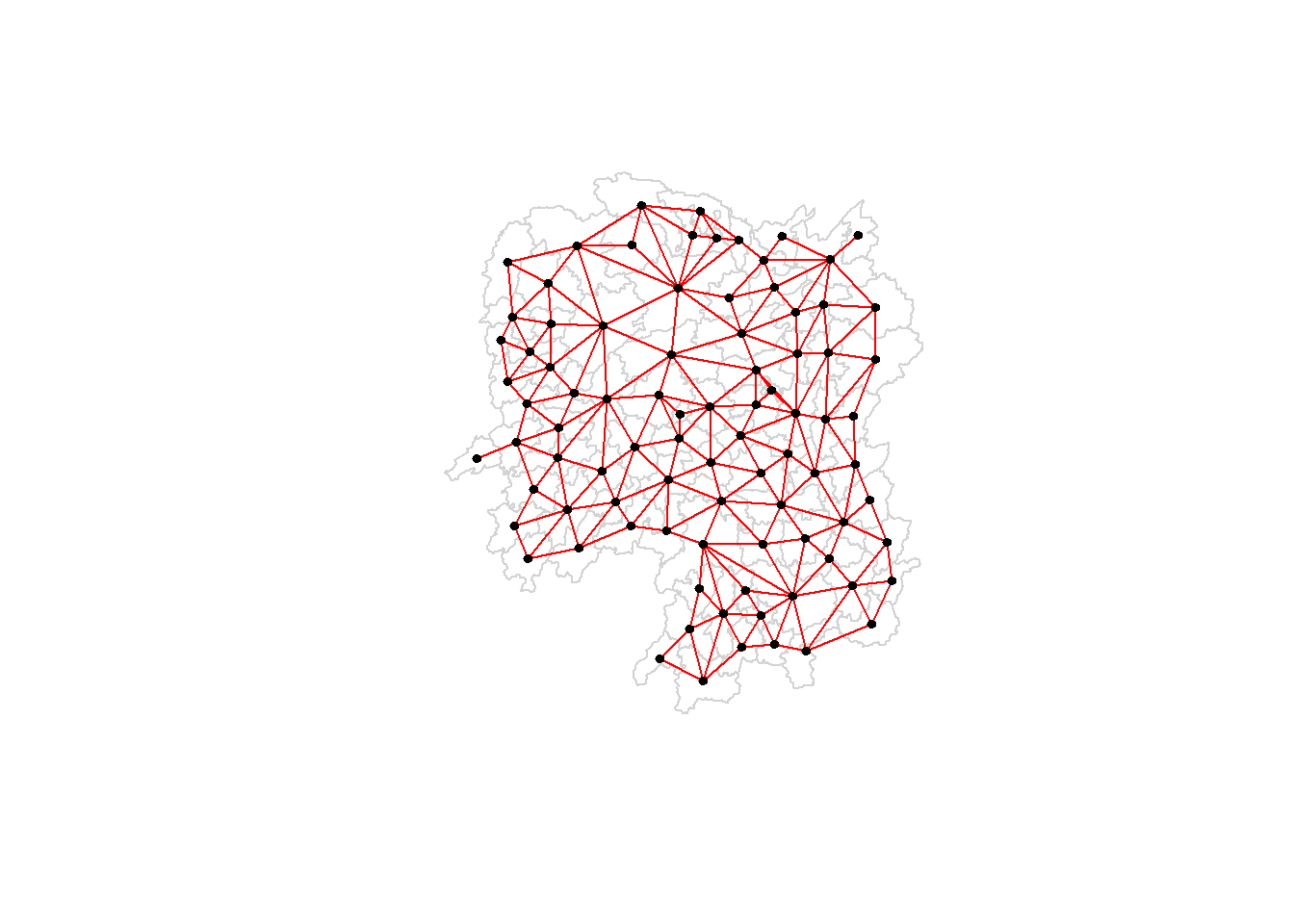
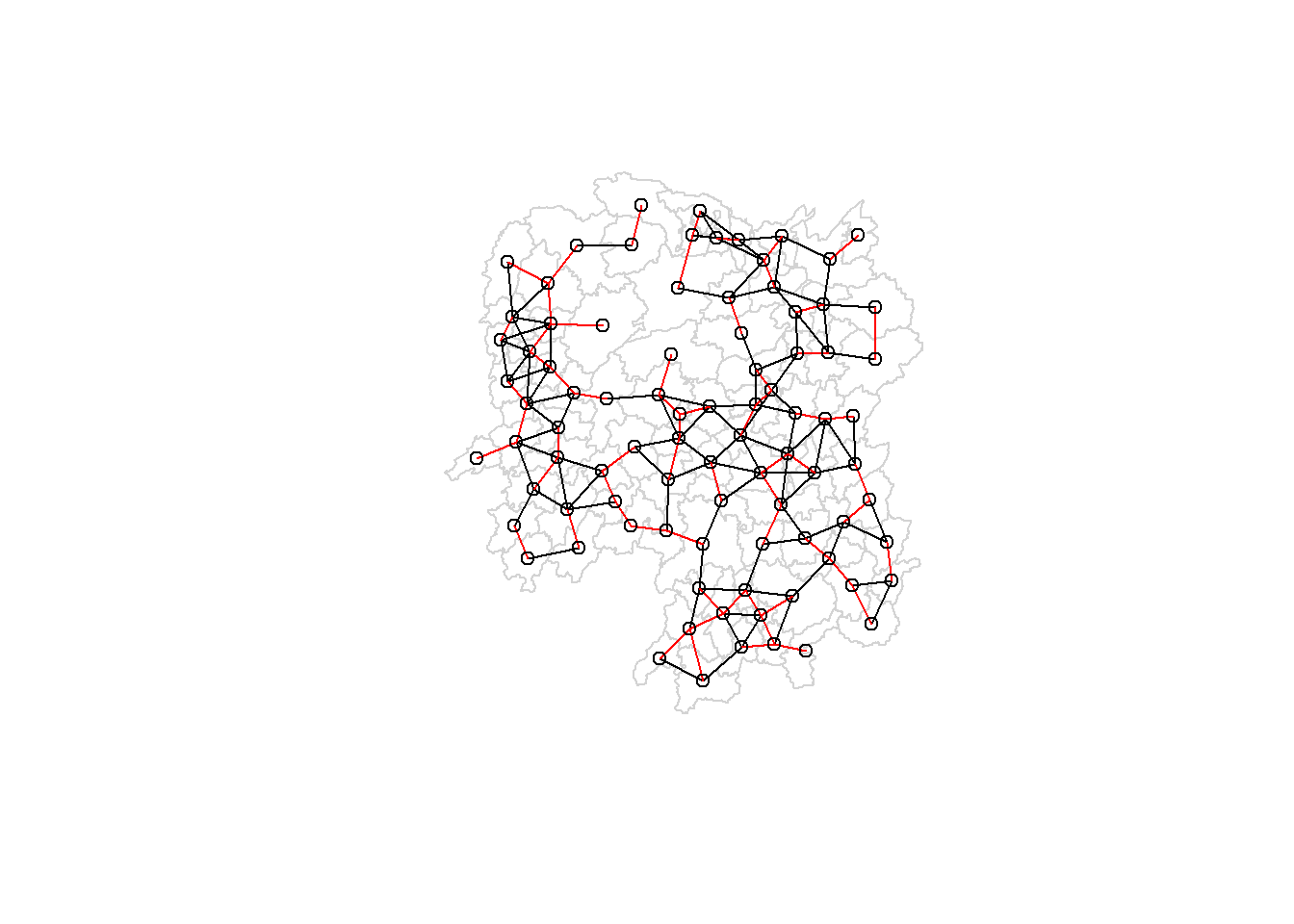
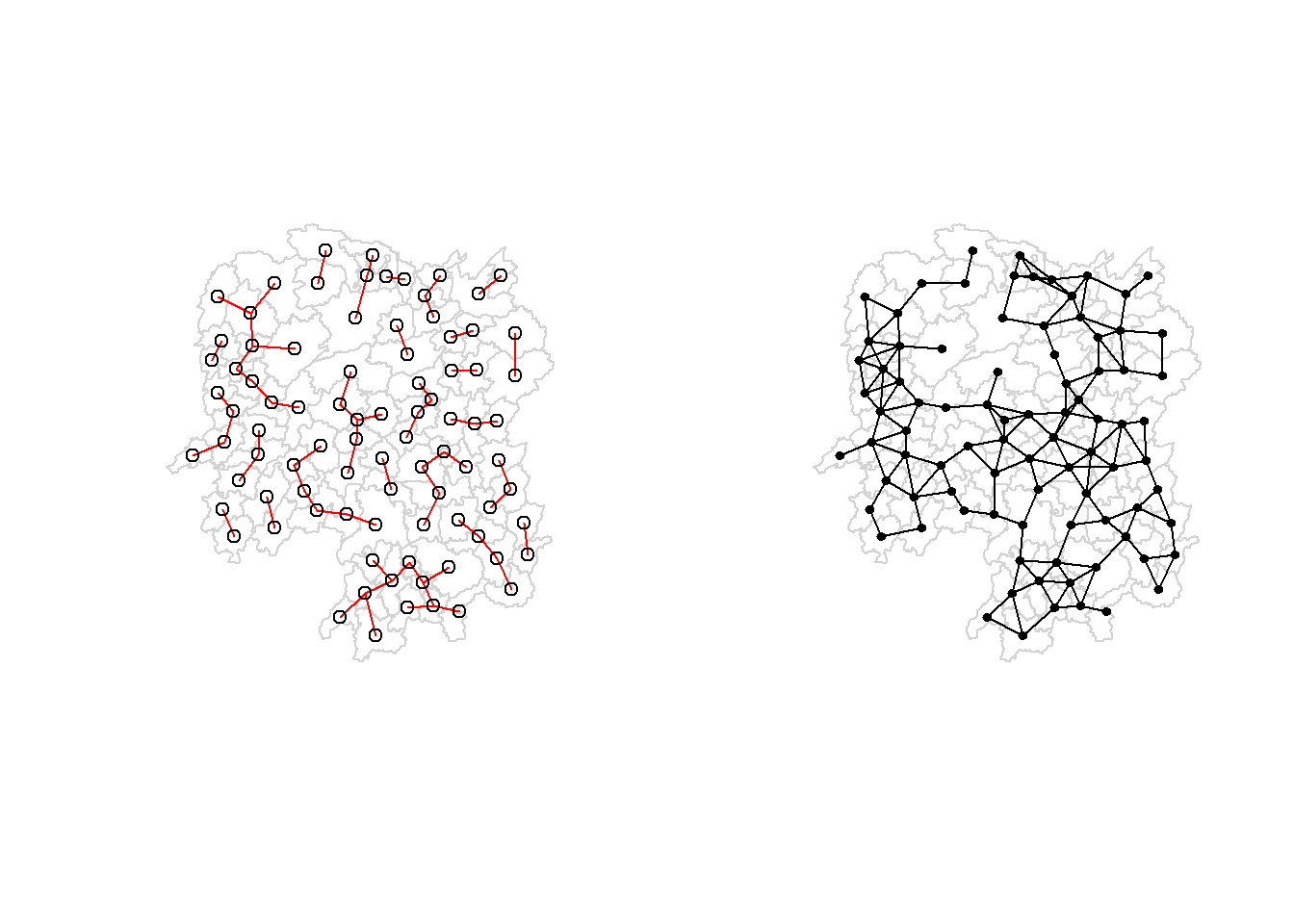
5.4.3 Visualising contiguity weights
A connectivity graph takes a point and displays a line to each neighboring point. One of the most common method to get points in order to make connectivity graphs is polygon centroids. Let us calculate these in the sf package before moving onto the graphs.
In this section, let us learn how to derive distance-based weight matrices by using dnearneigh() of spdep package.
5.5.1 Determine the cut-off distance
Firstly, let us determine the upper limit for distance band by using the steps below:
Return a matrix with the indices of points belonging to the set of the k nearest neighbours of each other by using knearneigh() of spdep.
Convert the knn object returned by knearneigh() into a neighbours list of class nb with a list of integer vectors containing neighbour region number ids by using knn2nb().
Return the length of neighbour relationship edges by using nbdists() of spdep. The function returns in the units of the coordinates if the coordinates are projected, in km otherwise.
Remove the list structure of the returned object by using unlist().
Min. 1st Qu. Median Mean 3rd Qu. Max.
24.79 32.57 38.01 39.07 44.52 61.79
The summary report shows that the largest first nearest neighbour distance is 61.79 km, so let us consider it as the upper threshold gives certainty that all units will have at least one neighbour.
5.5.2 Computing fixed distance weight matrix
Now, we will compute the distance weight matrix by using dnearneigh() as shown in the code chunk below.
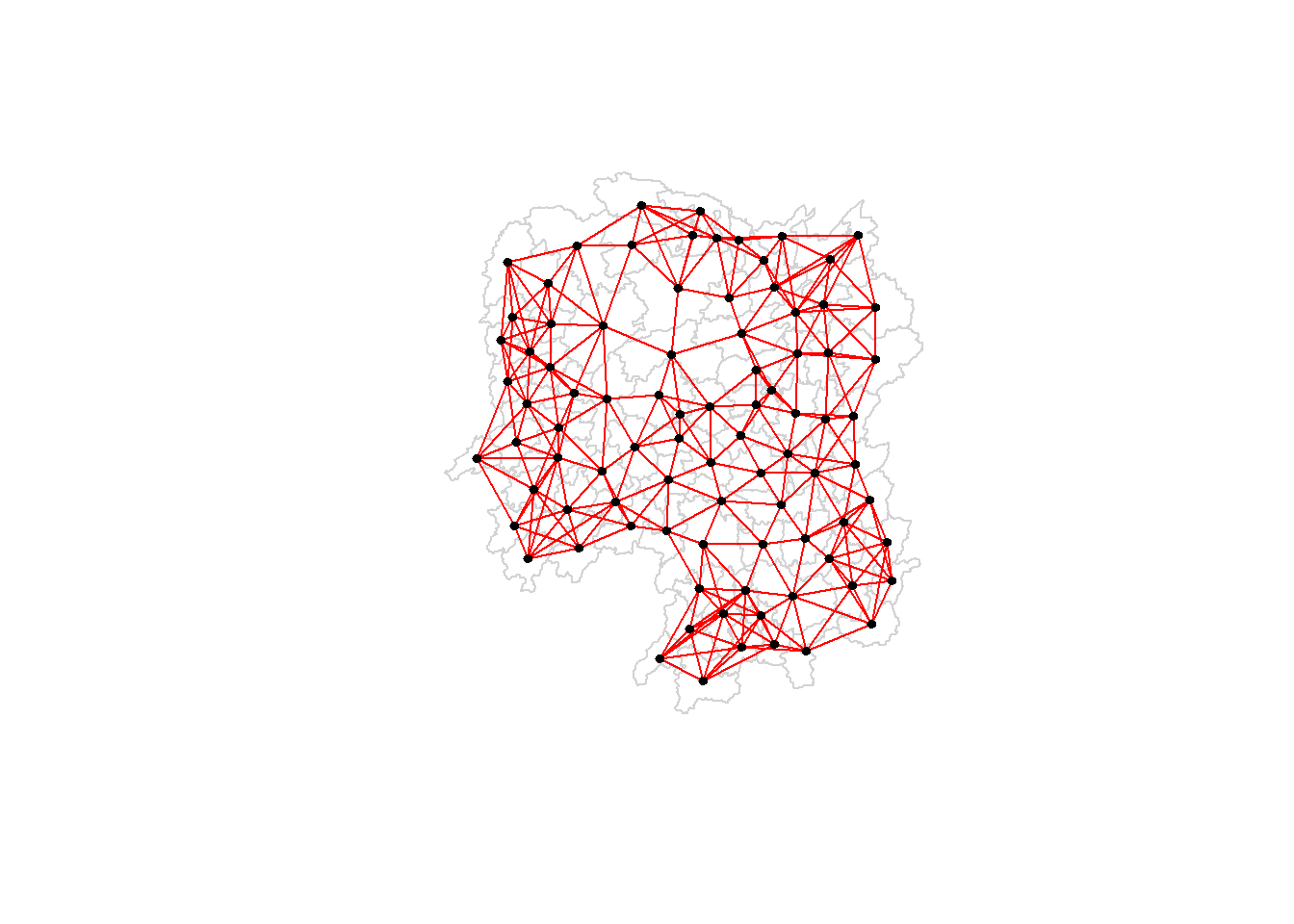
More densely settled areas (usually the urban areas) tend to have more neighbours and the less densely settled areas (usually the rural counties) tend to have lesser neighbours. Having many neighbours smoothes the neighbour relationship across more neighbours. It is possible to control the numbers of neighbours directly using k-nearest neighbours, either accepting asymmetric neighbours or imposing symmetry as shown in the code chunk below.
knn6 <-knn2nb(knearneigh(coords, k=6))knn6
Neighbour list object:
Number of regions: 88
Number of nonzero links: 528
Percentage nonzero weights: 6.818182
Average number of links: 6
Non-symmetric neighbours list
5.5.5 Plotting distance based neighbours
Let us plot the weight matrix using the code chunk below.
Characteristics of weights list object:
Neighbour list object:
Number of regions: 88
Number of nonzero links: 448
Percentage nonzero weights: 5.785124
Average number of links: 5.090909
Weights style: W
Weights constants summary:
n nn S0 S1 S2
W 88 7744 88 37.86334 365.9147
Characteristics of weights list object:
Neighbour list object:
Number of regions: 88
Number of nonzero links: 448
Percentage nonzero weights: 5.785124
Average number of links: 5.090909
Weights style: B
Weights constants summary:
n nn S0 S1 S2
B 88 7744 8.786867 0.3776535 3.8137
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.008218 0.015088 0.018739 0.019614 0.022823 0.040338
5.7 Application of Spatial Weight Matrix
In this section, let us see how to create four different spatial lagged variables,
spatial lag with row-standardized weights,
spatial lag as a sum of neighbouring values,
spatial window average, and spatial window sum.
5.7.1 Spatial lag with row-standardized weights
Finally, we’ll compute the average neighbor GDPPC value for each polygon. These values are often referred to as spatially lagged values. We can append the spatially lag GDPPC values onto hunan sf data frame by using the code chunk below.
We can calculate spatial lag as a sum of neighboring values by assigning binary weights. This requires us to go back to our neighbors list, then apply a function that will assign binary weights, then we use glist = in the nb2listw function to explicitly assign these weights.
Characteristics of weights list object:
Neighbour list object:
Number of regions: 88
Number of nonzero links: 448
Percentage nonzero weights: 5.785124
Average number of links: 5.090909
Weights style: B
Weights constants summary:
n nn S0 S1 S2
B 88 7744 448 896 10224
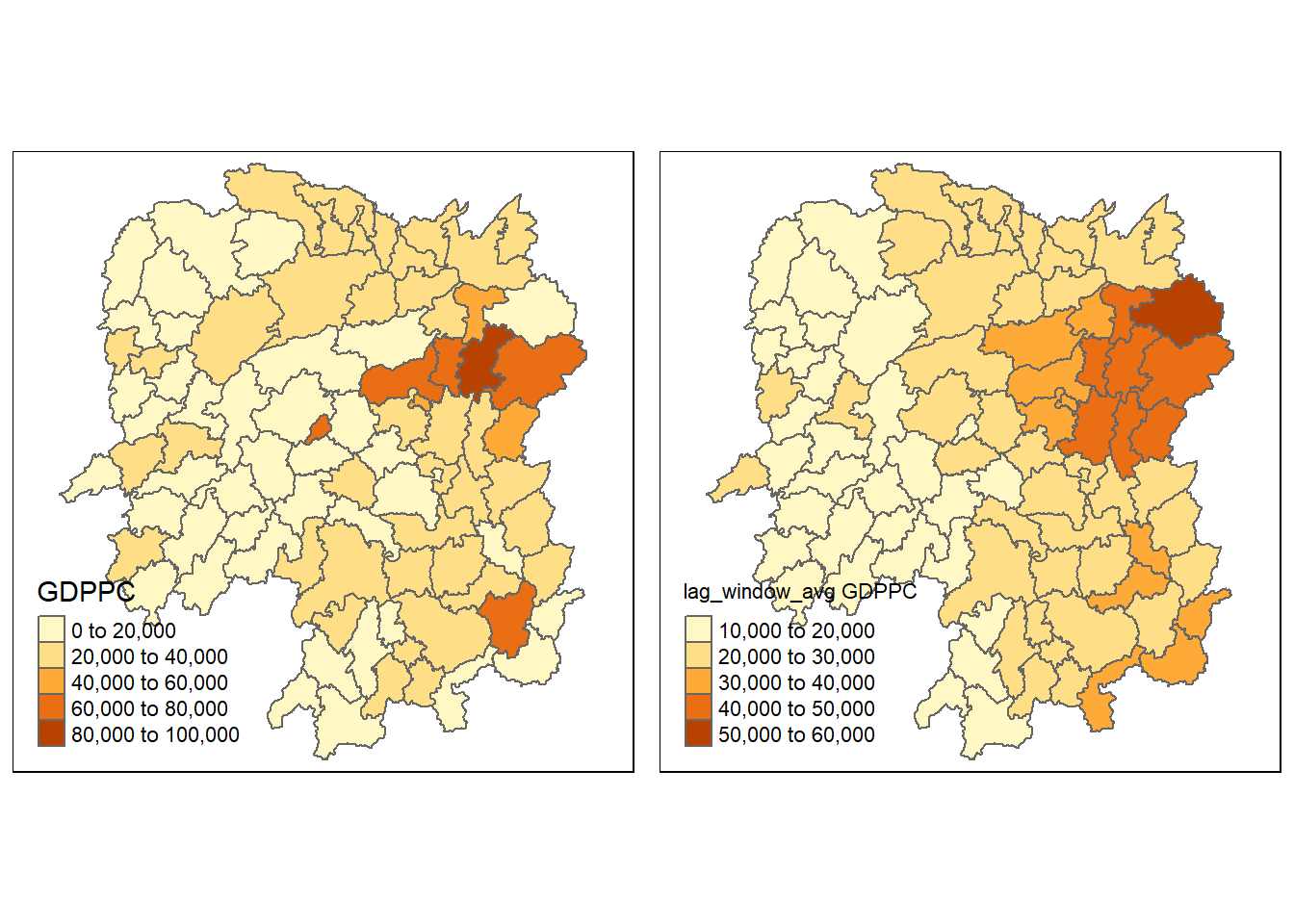
The spatial window average uses row-standardized weights and includes the diagonal element.
Firstly, let us assign k6 to a new variable because we will directly alter its structure to add the diagonal elements.
To add the diagonal element to the neighbour list, let us use include.self() from spdep.
As a next step, we have obtained weights with nb2listw()
Lastly, we just need to create the lag variable from our weight structure and GDPPC variable.
wm_q1 <- wm_qinclude.self(wm_q1)
Neighbour list object:
Number of regions: 88
Number of nonzero links: 536
Percentage nonzero weights: 6.921488
Average number of links: 6.090909
wm_q1 <-nb2listw(wm_q1)wm_q1
Characteristics of weights list object:
Neighbour list object:
Number of regions: 88
Number of nonzero links: 448
Percentage nonzero weights: 5.785124
Average number of links: 5.090909
Weights style: W
Weights constants summary:
n nn S0 S1 S2
W 88 7744 88 37.86334 365.9147
The spatial window sum is the counter part of the window average, but without using row-standardized weights.
Firstly, let us assign binary weights to the neighbor structure that includes the diagonal element. To add the diagonal element to the neighbour list, let us just use include.self() from spdep. Next, let us assign binary weights to the neighbour structure that includes the diagonal element Now, let us use nb2listw() and glist() to explicitly assign weight values.
wm_q1 <- wm_qinclude.self(wm_q1)
Neighbour list object:
Number of regions: 88
Number of nonzero links: 536
Percentage nonzero weights: 6.921488
Average number of links: 6.090909
wm_q1
Neighbour list object:
Number of regions: 88
Number of nonzero links: 448
Percentage nonzero weights: 5.785124
Average number of links: 5.090909
Characteristics of weights list object:
Neighbour list object:
Number of regions: 88
Number of nonzero links: 448
Percentage nonzero weights: 5.785124
Average number of links: 5.090909
Weights style: B
Weights constants summary:
n nn S0 S1 S2
B 88 7744 448 896 10224
In this section, we have seen what is spatial weights and how to compute spatial weights. We have also witnessed types of contiguity based neighbours and what are the applications of it. Finally we have learnt how to compute various types of spatially lagged variables and compare it with general ones. Now that we have understood about spatial weights, let us see how spatial weights are used for auto correlation in upcoming session. Stay tuned………………