Why regionalisation is vital? Clustering of multivariate water point attributes in Nigeria
1. Introduction
In the previous take home exercise 1, we have understood the dynamics of spatial patterns of non-functional water points in Nigeria and its diffusion over spatial boundaries with the help of appropriate global and local measures of spatial association techniques. In this exercise, let us emphasize on regionalisation. A regionalisation is a special kind of clustering where the objective is to group observations which are similar in their statistical attributes and in their spatial location.
2. Objective
The main aim of the study is to delineate homogeneous region of Nigeria by using geographically referenced multivariate waterpoint attributes data. Some of the major analysis include
Hierarchical cluster analysis
Spatially constrained cluster analysis using SKATER approach
Spatially constrained and Non-spatially constrained cluster analysis using ClustGeo
Spatially constrained cluster analysis using rgeoda
3. Glimpse of Steps
Some of the important steps performed in this study are as follows
Importing shapefile into R using sf package.
Deriving the proportion of functional and non-functional water point at LGA level using appropriate tidyr and dplyr methods.
Combining the geospatial and aspatial data frame into simple feature data frame.
Delineating water point measures functional regions by using conventional hierarchical clustering.
Delineating water point measures functional regions by using spatially constrained clustering algorithms.
Thematic Mapping - Plotting maps to show the water points measures derived by using appropriate statistical graphics and choropleth mapping technique.
Analytical Mapping - Plotting functional regions delineated by using both non-spatially constrained and spatially constrained clustering algorithms.
4. Data
For this study, data from WPdx Global Data Repositories and geoBoundaries are used which are in csv and shape file formats respectively. These datasets provide information about waterpoints and Nigeria’s Administrative boundary shape file.
Let us try to delineate homogeneous region of Nigeria by using geographically referenced multivariate waterpoint attributes data with sptially constrained and non-spatially constrained clustering methods
5.1 Loading packages
Let us first load required packages into R environment. p_load function pf pacman package is used to install the following packages into R environment.
sf, rgdal and spdep - Spatial data handling
tidyverse, especially readr, ggplot2 and dplyr - Attribute data handling
tmap - Choropleth mapping
coorplot, ggpubr, and heatmaply - Multivariate data visualisation and analysis
Now let us import geospatial data. The code chunk below uses st_read() function of sf package to import geoBoundaries-NGA-ADM2 shapefile into R environment.
Two arguments are used :
dsn - destination : to define the data path
layer - to provide the shapefile name
crs - coordinate reference system in epsg format. EPSG: 4326 is wgs84 Geographic Coordinate System
Importing geospatial data
nga <-st_read(dsn ="data2/geospatial",layer ="geoBoundaries-NGA-ADM2",crs =4326)
5.3 Importing Spatial Data
Now let us import spatial data. Since water point data set is in csv file format, we will use read_csv() of readr package to import Water_Point_Data_Exchange.csv as shown the code chunk below. The output R object is called listings and it is a tibble data frame.
filter() of dplyr package is used to extract water point records of Nigeria.
crs argument is to provide the coordinates system in epsg format. EPSG: 4326 is wgs84 Geographic Coordinate System EPSG: 26391 is Nigeria’s SVY21 Projected Coordinate System
Converting Projection
nga_sf <-st_transform(nga,crs =26391)
st_transform() of sf package is used to reproject nga from one coordinate system(WGS 84) to another coordinate system(ESPG) mathemetically.
5.5 Data Wrangling
Before finalising the data, we have to perform some data cleaning
5.5.1 Checking for duplicate values
Thanks to our classmate, who have identified the right location for duplicate values with the help of google map data. Reference link
duplicated() function returns a logical vector where TRUE specifies which elements of a vector or data frame are duplicates.
filter() function filters those duplicates and lets check what are the duplicated shape Names
The output is zero which means there are no duplicate values now.
5.5.2 Combining geospatial and aspatial data
Let us now use a geoprocessing function (or commonly know as GIS analysis) called point-in-polygon overlay to transfer the attribute information in nga sf data frame into wp_sf data frame using st_join()function.
combining data
wp_sf <-st_join(wp_nga_sf, nga_sf)
5.5.3 Measures used for regionalisation
Based on the WPdx standard, following measures are chosen,
Table 2: Clustering Attributes
Measure
col_id
Description
Total number of functional water points
#status_clean
No. of functional waterpoints are derived from this categorised column
Total number of nonfunctional water points
#status_clean
No. of non- functional waterpoints are derived from this categorised column
Percentage of functional water points
#status_clean
Percentage of functional waterpoints are derived from the already derived columns
Percentage of non-functional water points
#status_clean
Percentage of non-functional waterpoints are derived from the already derived columns
Percentage of main water point technology
#water_tech_clean
Describe the system being used to transport the water from the source to the point of collection (e.g. Handpump)
Percentage of usage capacity
usage_cap
Recommended maximum users per water point. For eg. 250 people per tap [tapstand, kiosk, rainwater catchment] 500 people per hand pump.
Percentage of rural water points
is_urban
Is in an urban area as defined by EU Global Human Settlement Database TRUE/FALSE - urban/rural
Percentage of crucial waterpoints
crucialness_score
crucialness score shows how important the water point would be if it were to be rehabilitated.
Percentage of stale waterpoints
staleness_score
The staleness score represents the depreciation of the point’s relevance. Varies between 0 and 100. Higher the value more the staleness.
5.5.4 Renaming the column names
Let us rename some of the column names which begins with # for ease of use by using rename() function
There are water technology values mentioned along with the manufacturer like India Mark III, Afridev. So lets recode all those manufacturers into one class as Hand Pump using recode() function
Recoding handpumps
wp_nga <-wp_nga %>%mutate(wpt_tech=recode(water_tech, 'Hand Pump - Rope Pump'='Hand Pump','Hand Pump - India Mark III'='Hand Pump','Hand Pump - Afridev'='Hand Pump','Hand Pump'='Hand Pump','Hand Pump - India Mark II'='Hand Pump','Hand Pump - Mono'='Hand Pump'))
5.5.6 Extracting Funtional, Non-Functional and Unknown water points
As our objective is to focus on waterpoints, let us extract the three types and save it as a dataframe for further analysis
Extracting waterpoints
wpt_functional <- wp_nga %>%filter(status_cle %in%c("Functional", "Functional but not in use","Functional but needs repair"))wpt_nonfunctional <- wp_nga %>%filter(status_cle %in%c("Abandoned/Decommissioned", "Abandoned","Non-Functional","Non functional due to dry season","Non-Functional due to dry season"))wpt_unknown <- wp_nga %>%filter(status_cle =="Unknown")handpump <- wp_nga %>%filter(wpt_tech =="Hand Pump")usecap_lessthan1000 <- wp_nga %>%filter(usage_capacity <1000)usecap_greatthan1000 <- wp_nga %>%filter(usage_capacity >=1000)wpt_rural <- wp_nga %>%filter(is_urban ==FALSE)crucial_score <- wp_nga %>%filter(crucialness_score >=0.5)stale_score <- wp_nga %>%filter(staleness_score >=50)
5.5.7 Computing absolute numbers
We have to perform 2 steps to calculate the absolue numbers of waterpoint attributes in each division.
Let us identify no. of waterpoints located inside each division by using st_intersects().
Next, let us calculate numbers of pre-schools that fall inside each division by using length() function.
Before performing spatial analysis, let us first do some preliminary data analysis to understand the data better in terms of water points.
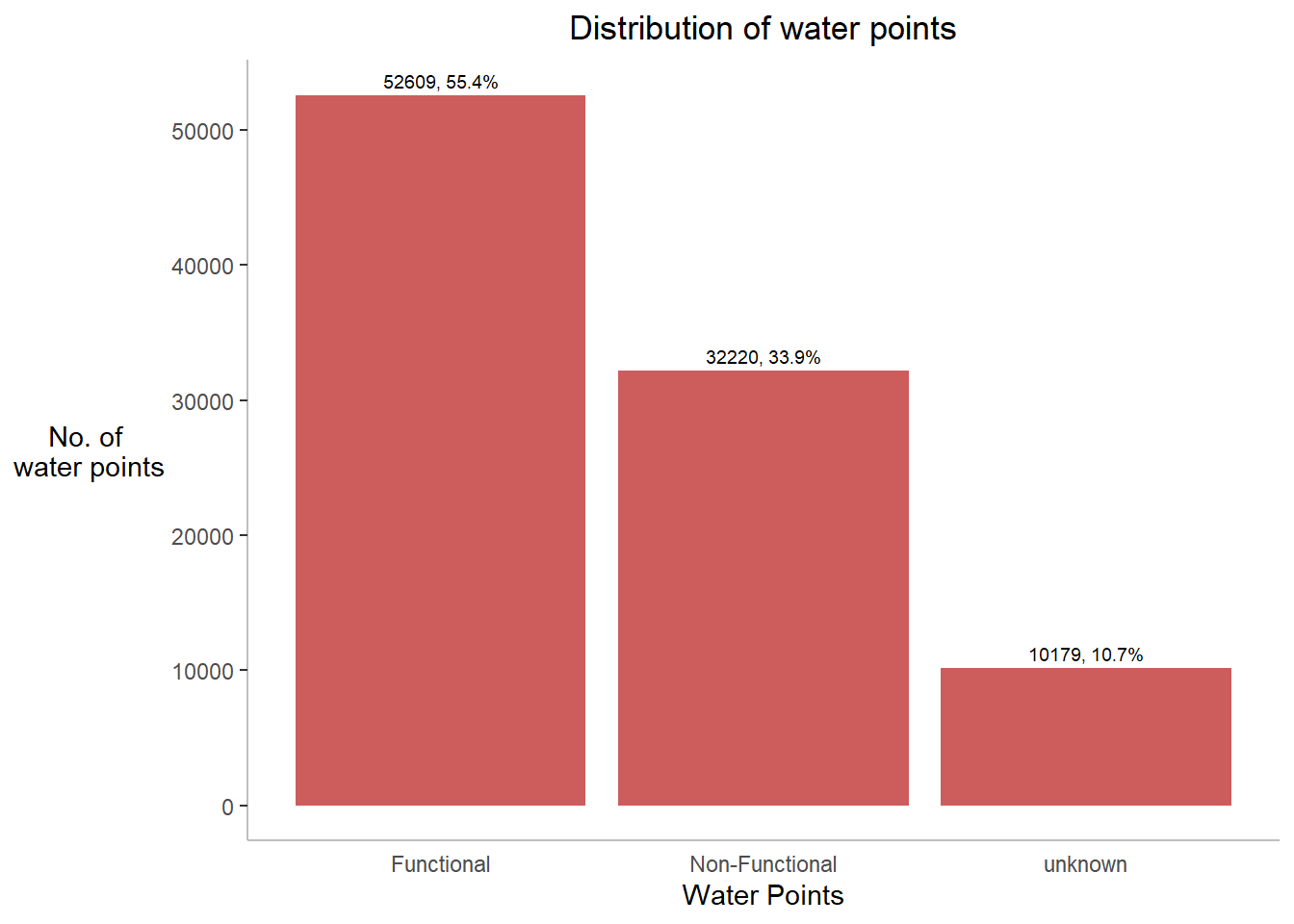
5.6.1 What is the proportion of functional and non-functional water points?
Before visualising, its important for us to prepare the data. Based on WPDx Data Standard, the variable ‘#status_id’ refers to Presence of Water when Assessed. Binary response, i.e. Yes/No are recoded into Functional / Not-Functional.
ggarrange() function of ggpubr package is used to group these bargraphs together.
ggarrange(tp1, tp2, tp3, tp4,ncol=2,nrow=2)
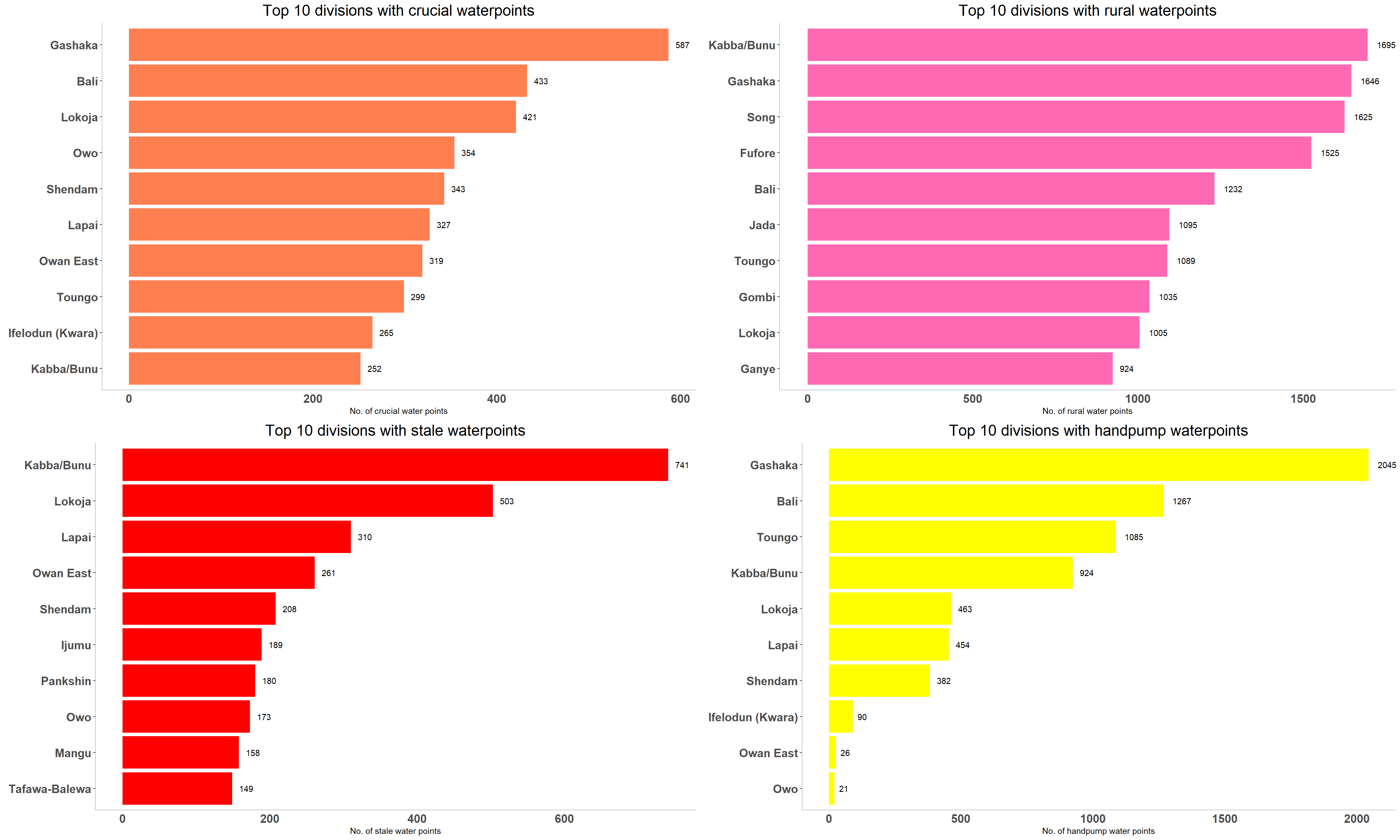
Insights:
We can infer that divisions like Bali, Gashaka, Toungo are matter of concern as they have most no. of crucial water points i.e.the crucialness score shows how important the water point would be if it were to be rehabilitated, most of which are rural and also these divisions have highest no. of waterpumps.
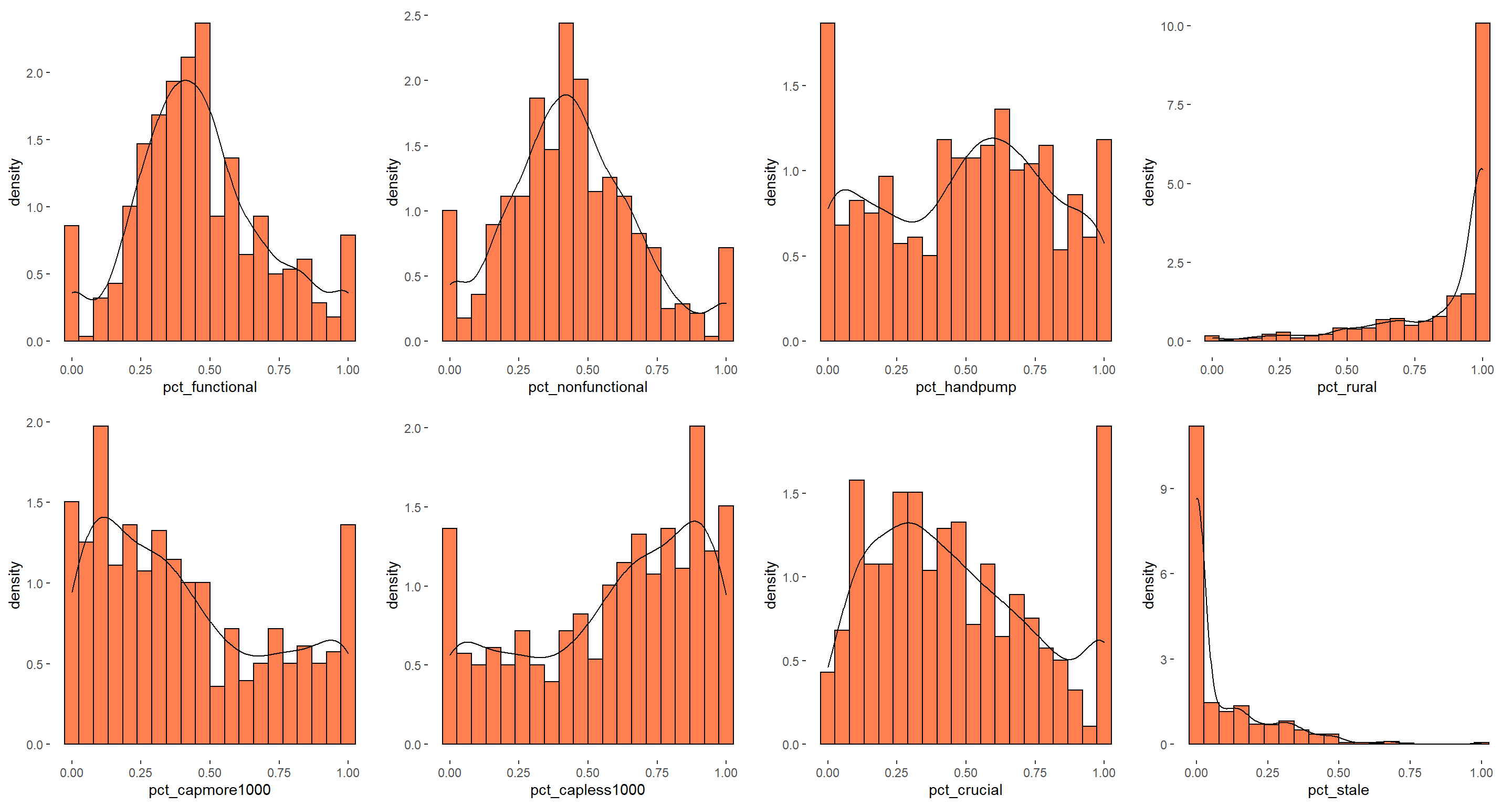
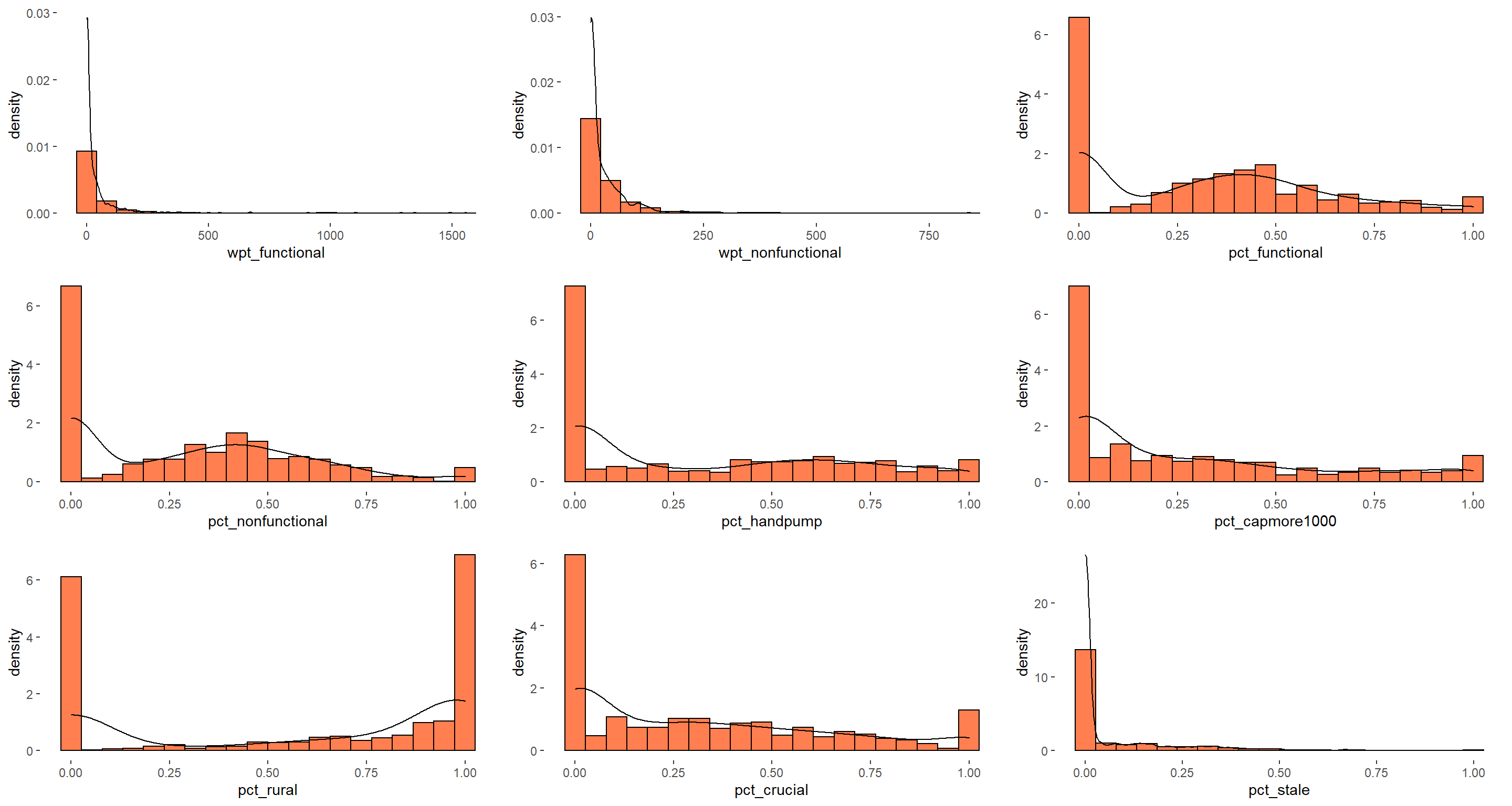
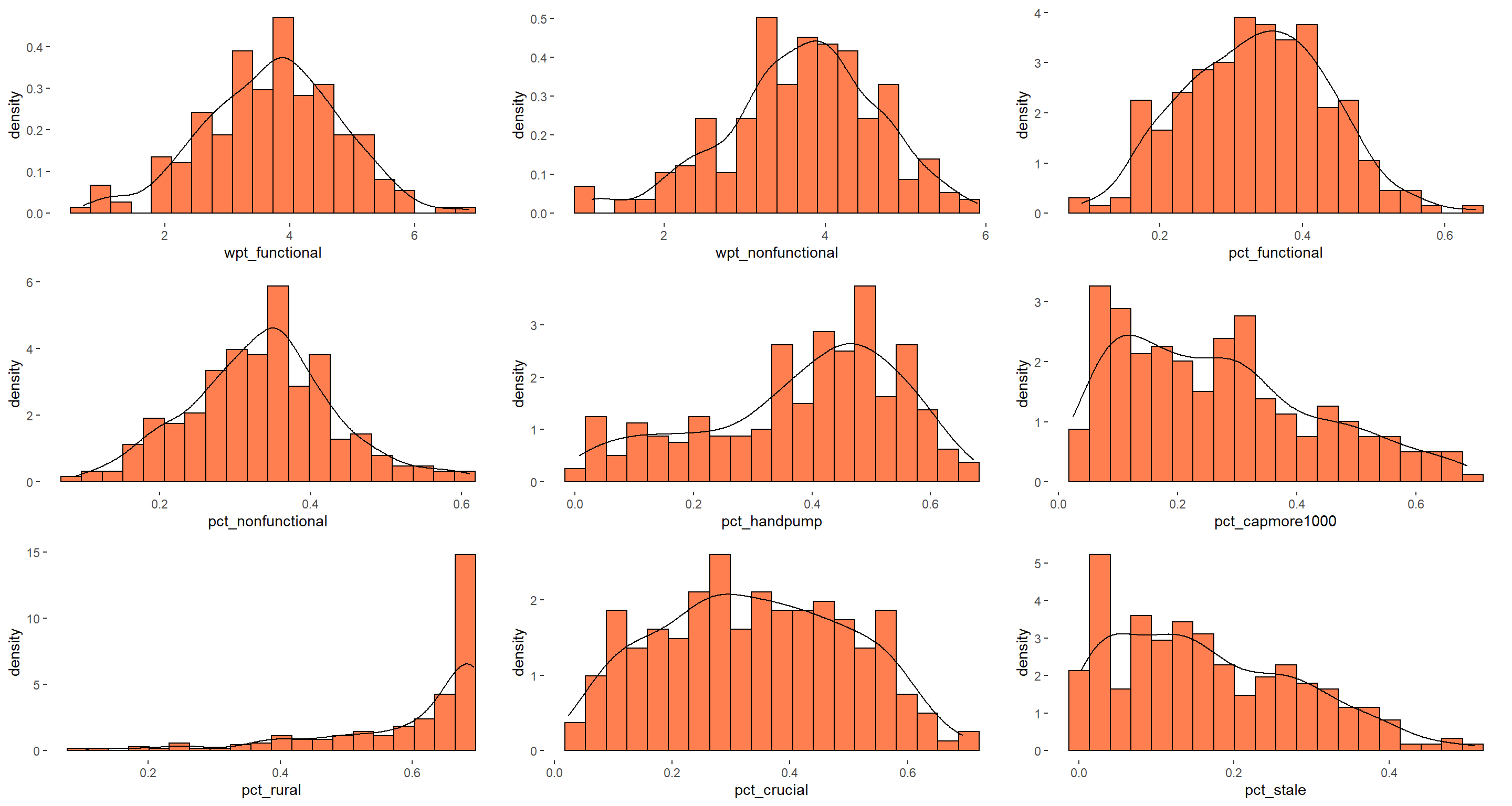
5.6.3 What is the distribution of waterpoint proportion attributes?
The code chunks below are used to create multiple histograms to reveal the overall distribution of the selected variables in nga_wp_clus. They consist of two main parts.
Create the individual histograms using geom_histogram() and geom_density() functions
Group these histograms together by using the ggarrange() function of ggpubr package
We can observe that distribution of rural waterpoints proportion is left skewed and distribution of proportion of staleness waterpoints is right skewed. The distribution is not normal for all except pct_functional and pct_nonfunctional
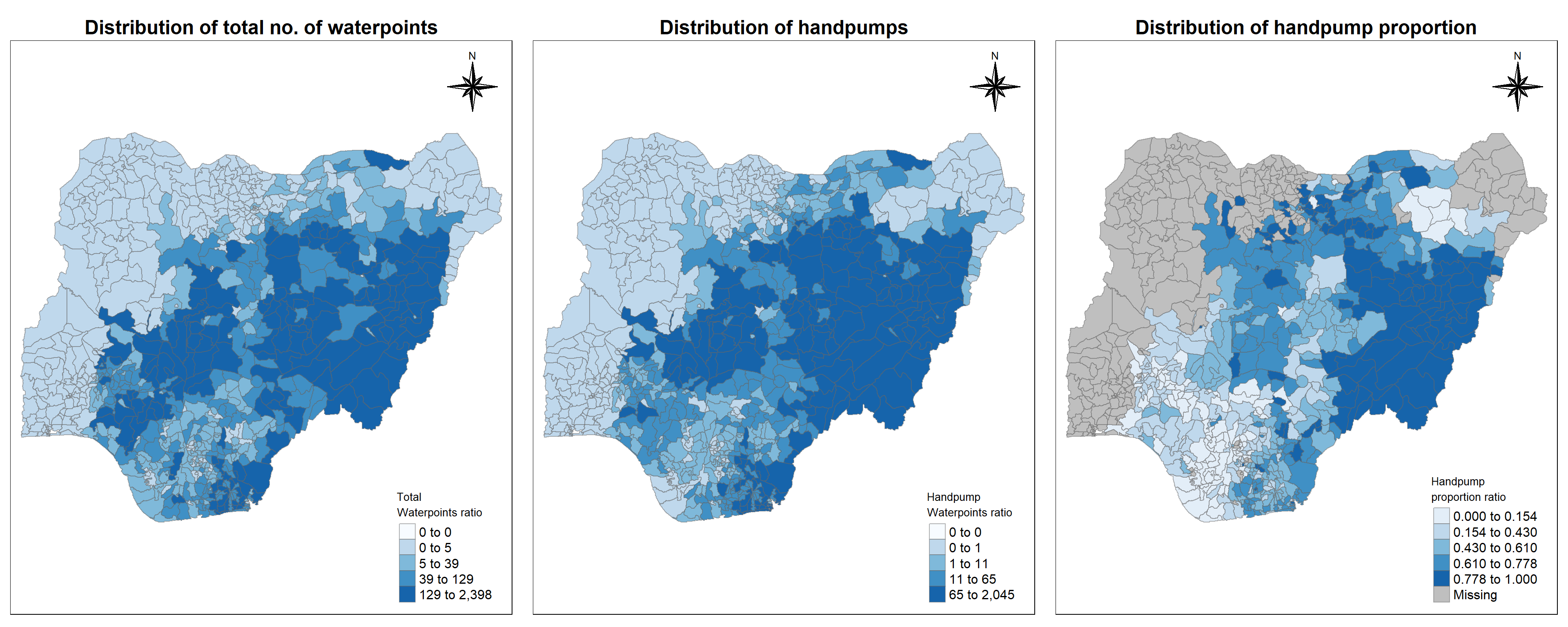
5.6.4 How is the handpump proportion spread across the country?
Previously, we have performed preliminary data analysis using statistical charts. Now let us visualise it using maps.
Total waterpoints spread
cm1 <-tm_shape(nga_wp_clus)+tm_fill("total_wpt", style ="quantile", palette ="Blues",title ="Total \nWaterpoints ratio") +tm_layout(main.title ="Distribution of total no. of waterpoints",main.title.position ="center",main.title.size =1.5,legend.height =1, legend.width =1,legend.text.size =1,legend.title.size =1,main.title.fontface ="bold",frame =TRUE) +tmap_mode("plot")+tm_borders(alpha =0.5) +tm_compass(type="8star",position=c("right", "top"))
Individual maps are combined using tmap_arrange() function
tmap_arrange(cm1, cm2, cm3, ncol=3)
Insights:
It is evident that the second map is almost similar to first map because if we take absolute numbers into consideration, no. of handpumps will be obviously higher in the places where there are more no. of waterpoints. For example, central and eastern Nigeria has most no. of handpumps .Whereas, the third map shows handpumps proportion in central region is comparatively lower than western region.
5.7 Clustering Analysis - Preparation
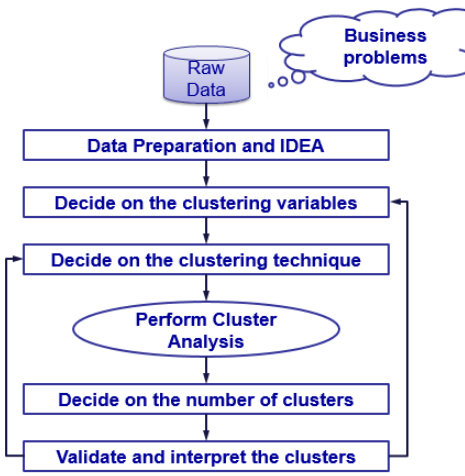
The below figure shows a basic framework for cluster analysis and the steps involved in the process.
Fig 1- Steps involved in cluster analysis
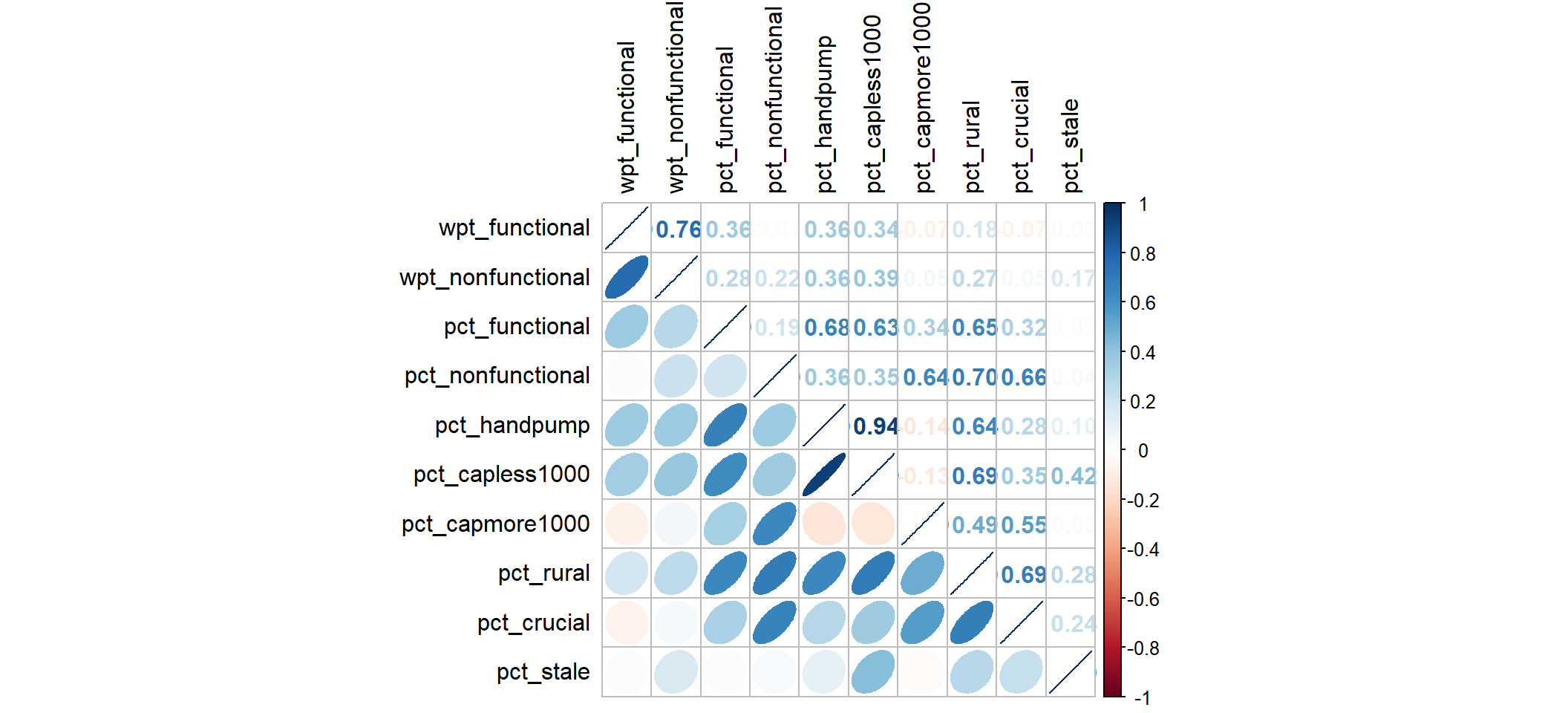
Are there any highly correlated cluster variables?
Let us ensure that the cluster variables are not highly correlated.
The code chunk below helps us to visualise and analyse the correlation of the input variables by using corrplot.mixed() function of corrplot package.
In general, if correlation coefficient value is greater than 0.85 then the variables are said to be highly correlated. In that case, here, pct_handpump and pct_capless1000 is highly correlated as the magnitude of corelation coefficient is 0.94. Hence, let us exclude the cluster variable pct_capless1000.
Extracting cluster variables
As per the flowchart, we have so far completed first step. Let us decide on the clustering variables.
The below code chunk is to extract and save the clustering variables in a separate dataframe.
Drop geometry from the dataframe using st_set_geometry() function
Choose the desired columns by using select() clause
Replace the NA values by 0 using replace(is.na()) function
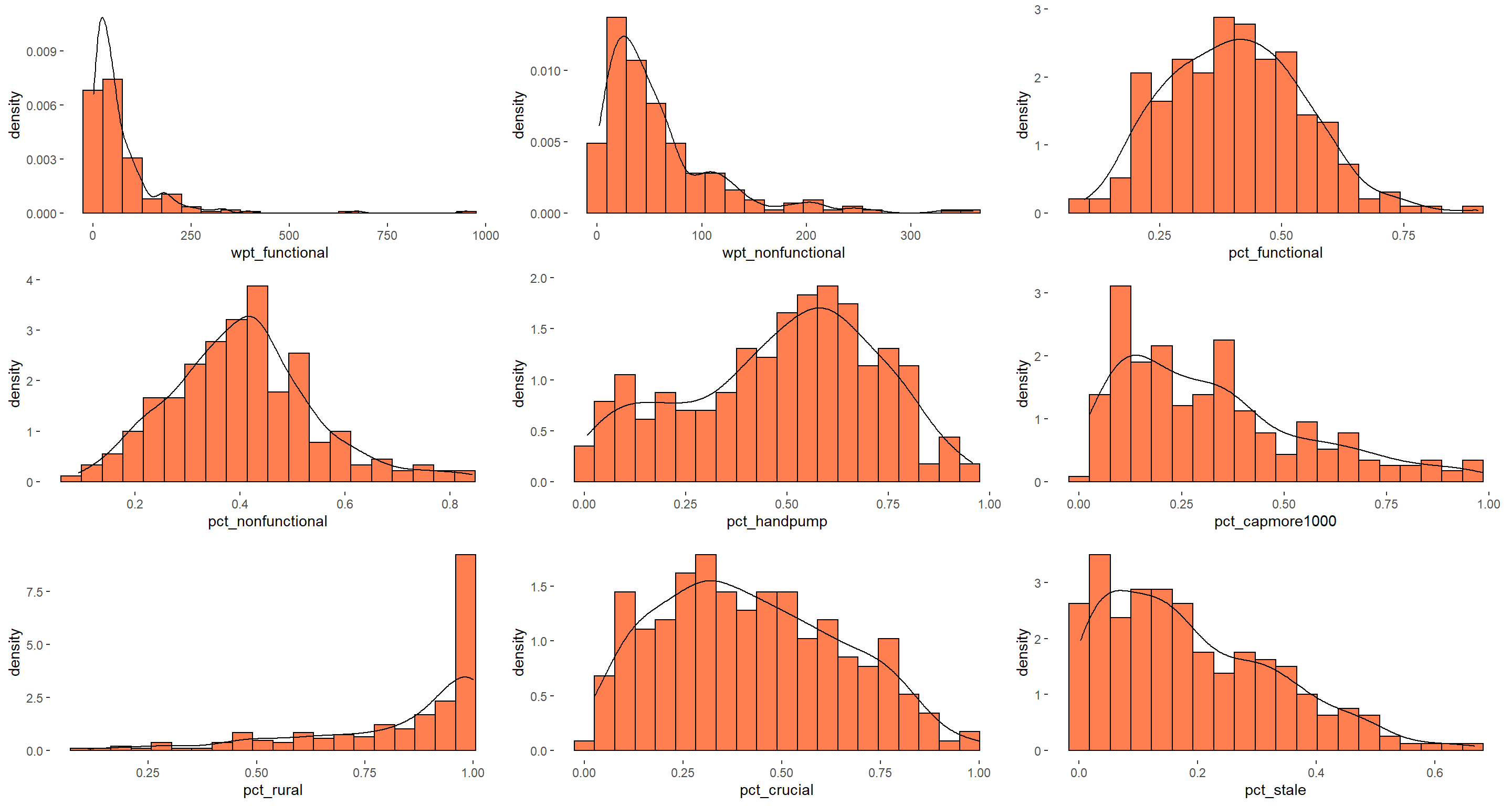
Cluster variables with large variances tend to have a greater effect on the resulting clusters than those with small variances. Hence, before performing cluster analysis we should examine the distribution of the cluster variables using appropriate exploratory data analysis techniques, such as histogram.
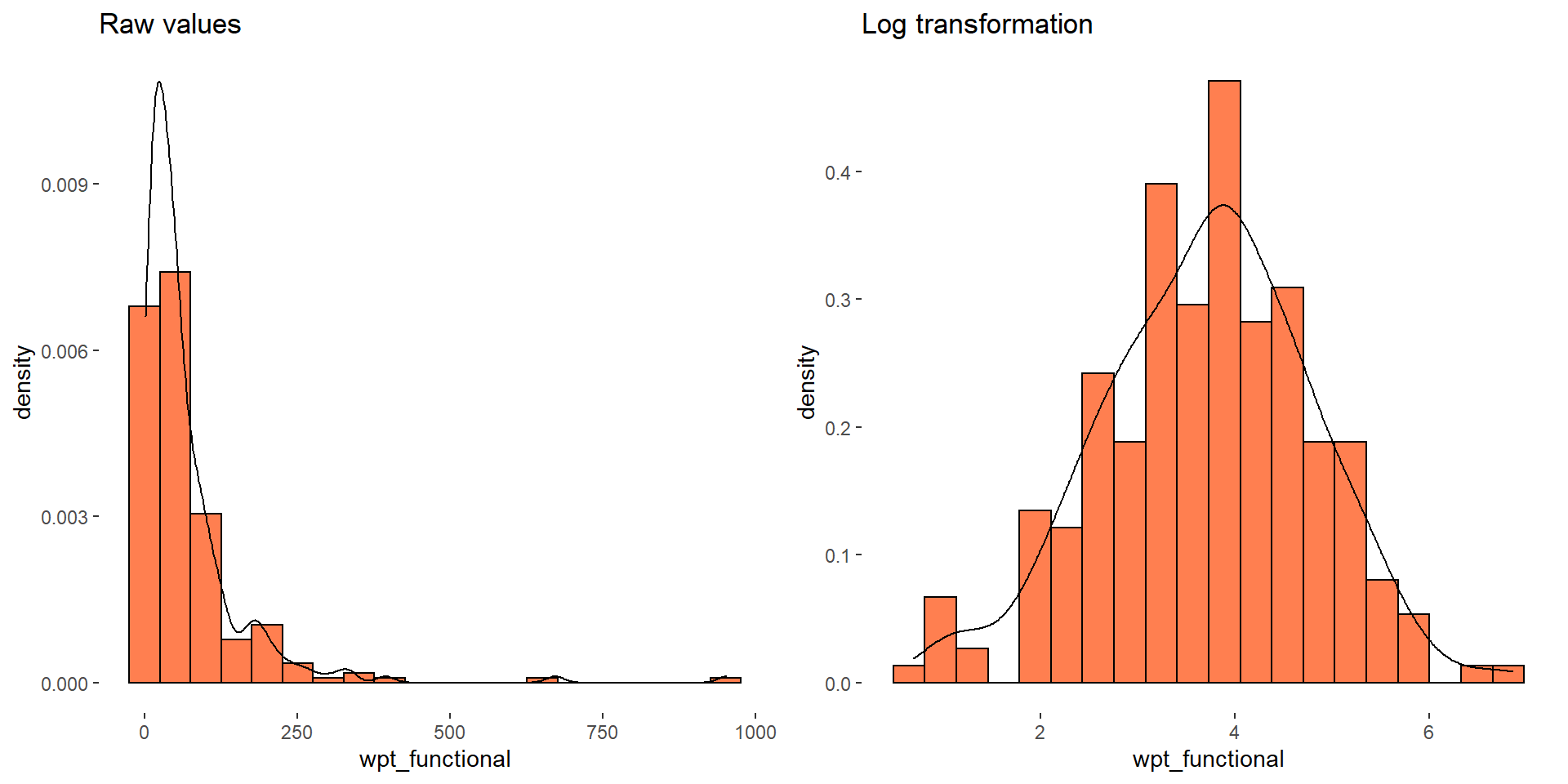
Distribution of attributes like pct_functional, pct_nonfunctional are normal whereas wpt_functional, wpt_non_functional are right skewed, pct_rural distribution is left skewed. Let us perform transformation to convert it into normal distribution
After performing log transformation, now the distribution is normal. For eg, let us compare the distribution of wpt_functional before and after transformation
The skewness is removed and the distribution has become normal
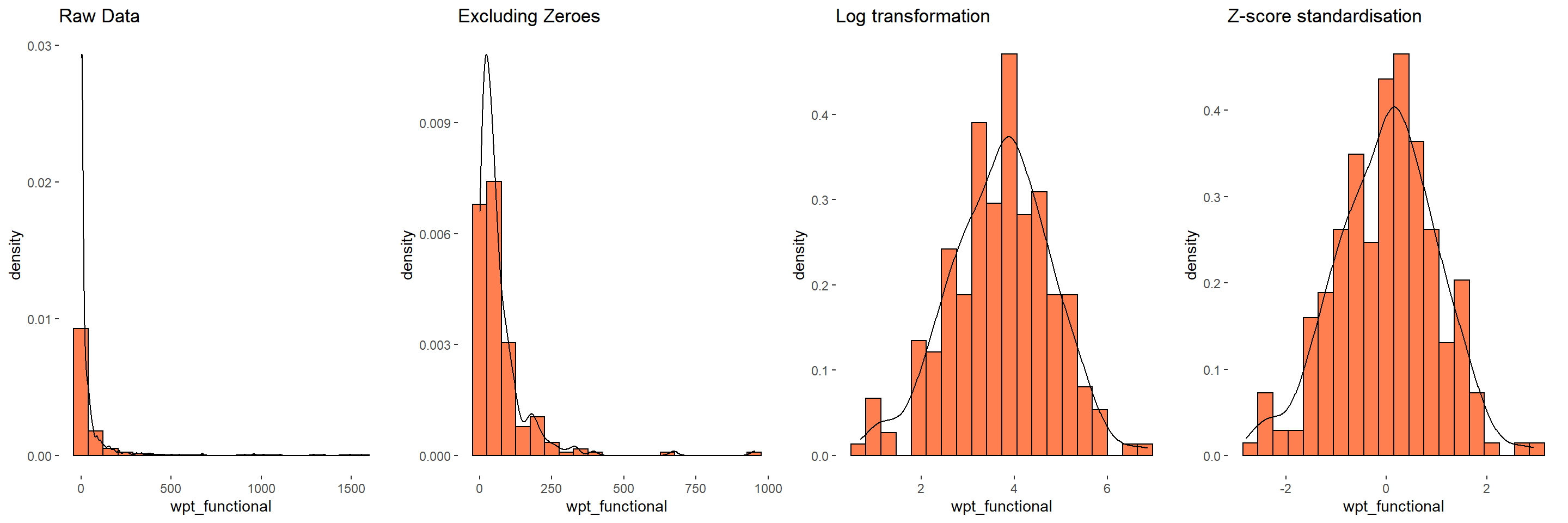
Data Standardisation
As our clustering variables include absolute numbers and percentage values, it is obvious that their values range are different. In order to avoid the cluster analysis result is baised to clustering variables with large values, it is useful to standardise the input variables before performing cluster analysis.
There are 3 major standardisation techniques
Standardisation techniques
Here, we are performing Z-score standardisation as it can handle outliers well and it is applicable to variables which are from normal distribution
Hence, we have transformed the variables so as to have normal distribution and performed z-score standardisation to maintain same ranges among all variables.
Computing Proximity Matrix
A proximity matrix is a square matrix (two-dimensional array) containing the distances, taken pairwise between the elements of a matrix. Broadly defined; a proximity matrix measures the similarity or dissimilarity between the pairs of matrix.
Major types are euclidean, maximum, manhattan, canberra, binary and minkowski.
The code chunk below is used to compute the proximity matrix using dist() function and euclidean method.
Proximity matrix
proxmat <-dist(nga_derived, method ='euclidean')
5.8 Hierarchical Clustering
Determining optimal algorithm
While performing hierarchical clustering we have to identify the strongest clustering structures.
The code chunk below will be used to compute the agglomerative coefficients of all hierarchical clustering algorithms.
average single complete ward
0.9934065 0.9892576 0.9959162 0.9986306
We can see that Ward’s method provides the strongest clustering structure among the four methods assessed. Hence, let us use the same in the subsequent analysis.
Determining optimal clusters
There are three commonly used methods to determine the optimal clusters, they are:
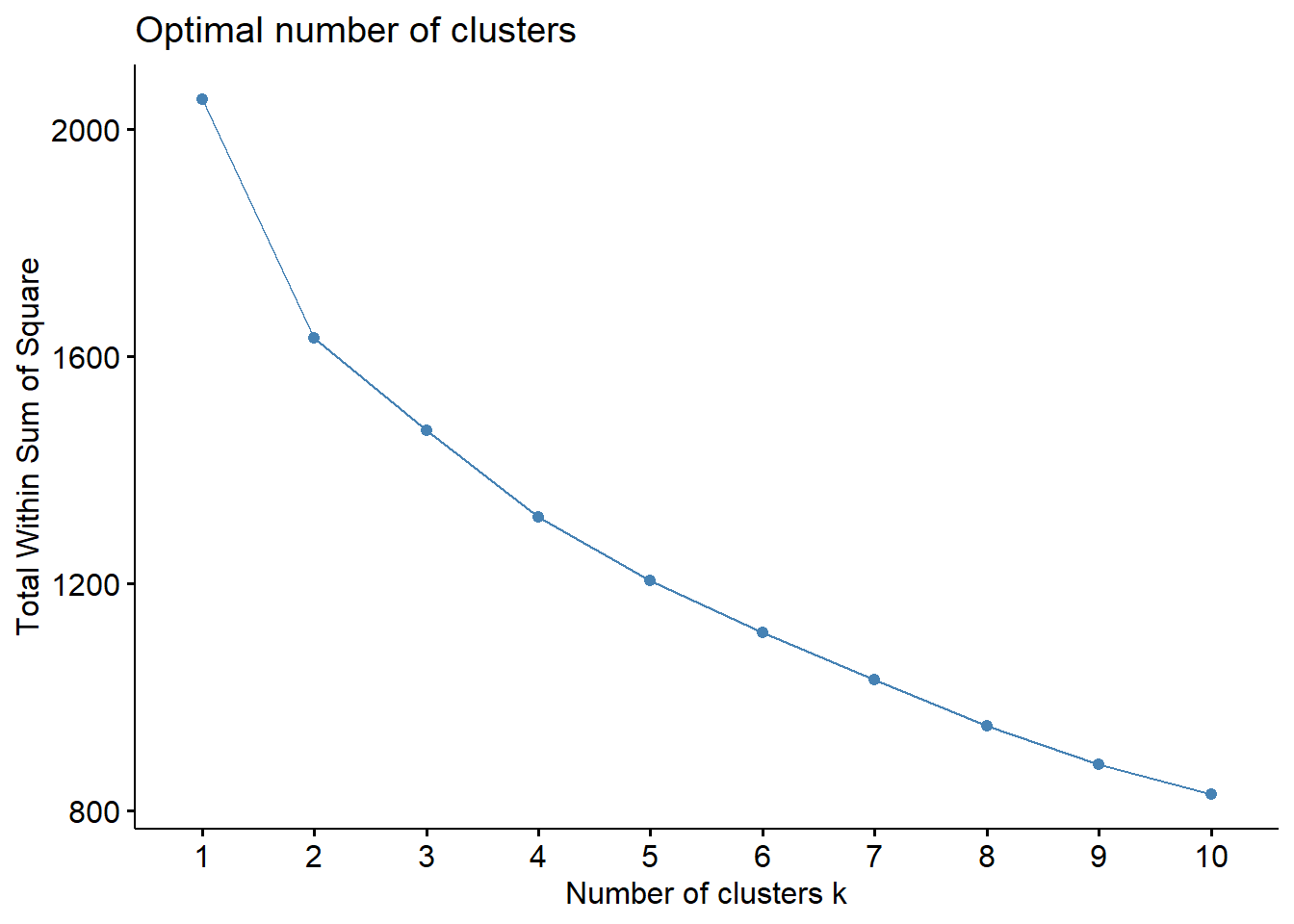
Let us use Elbow Method to determine optimal no. of clusters.
fviz_nbclust() of factoextra package - to specify the no. of clusters to be generated
method - wss - within sum of squares
Elbow method
fviz_nbclust(nga_derived.z, hcut, method ="wss")
Min no. of clusters required to perform clustering analysis is 3. The plot reveals that optimal no. of clusters is 4 as the slope reduces gradually.
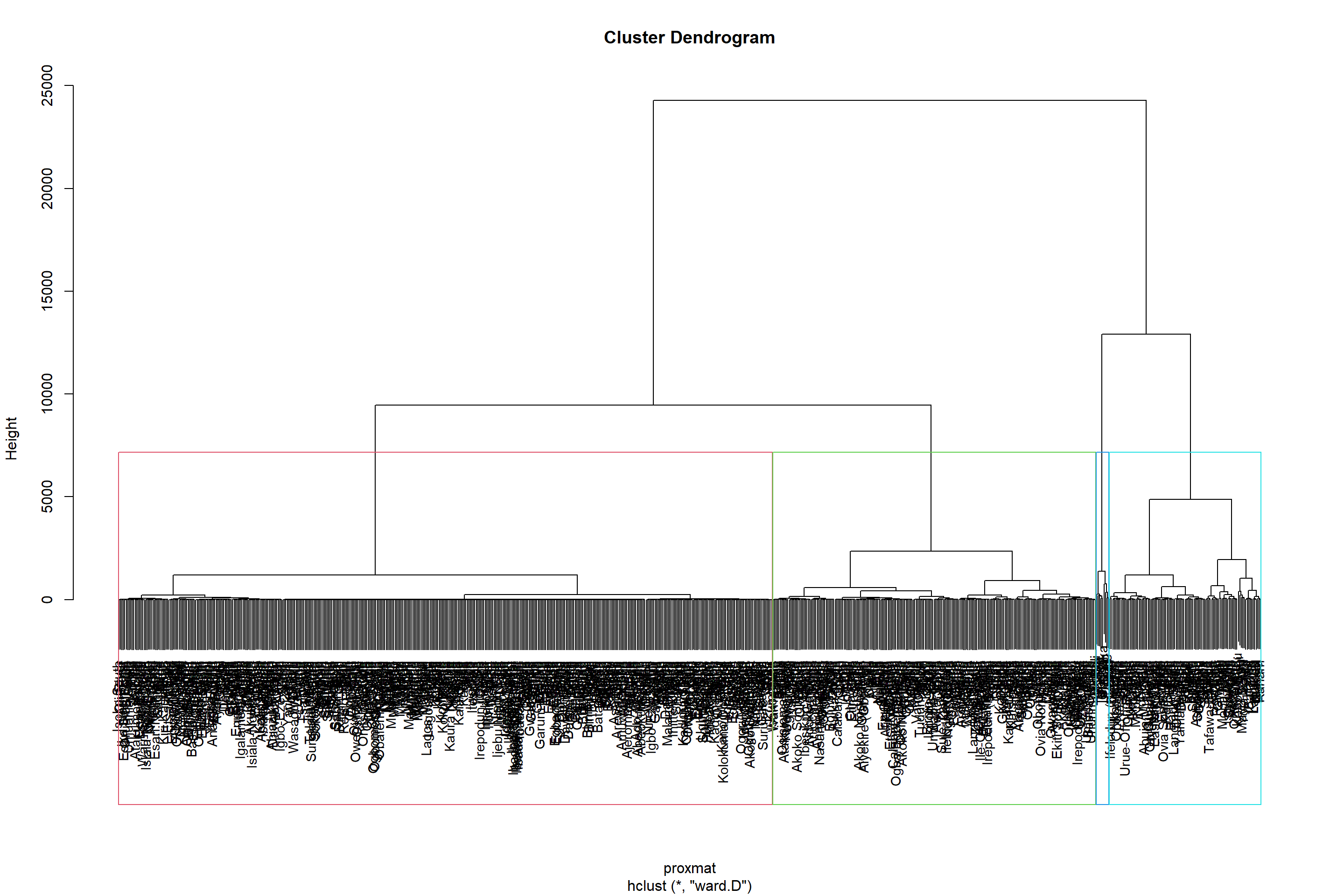
Creating dendrogram
In the dendrogram displayed below, each leaf corresponds to one observation. As we move up the tree, observations that are similar to each other are combined into branches, which are themselves fused at a higher height. The code chunk below performs hierarchical cluster analysis using ward.D method. The hierarchical clustering output is stored in an object of class hclust which describes the tree produced by the clustering process. rect.hclust() - to draw the dendrogram with a border around the selected clusters
border - to specify the border colors for the rectangles
Dendrogram
set.seed(3456)hclust_ward <-hclust(proxmat, method ='ward.D')plot(hclust_ward, cex =0.9)rect.hclust(hclust_ward, k =4, border =2:5)
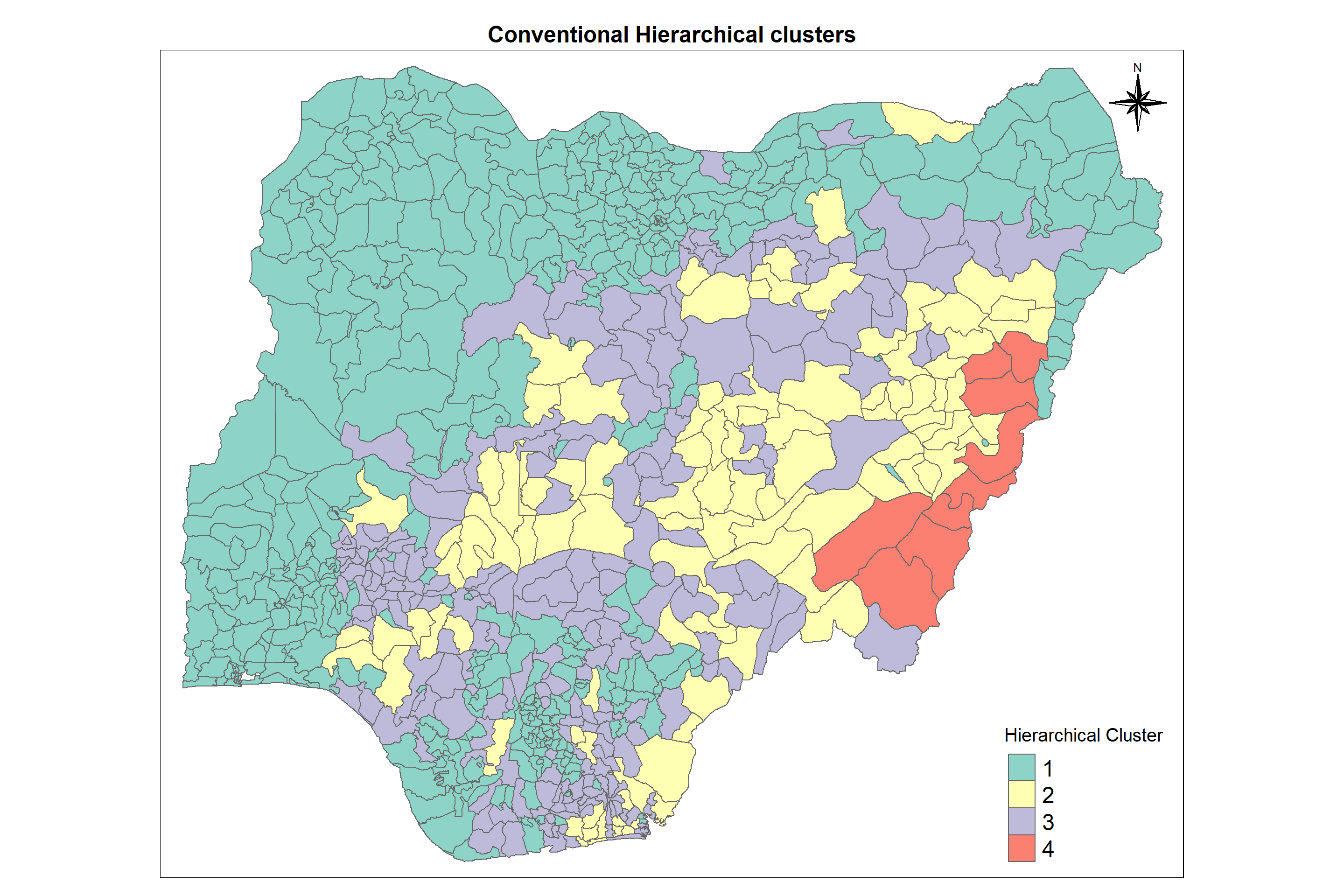
Visual interpretation of clusters - Spatial Map
We are retaining 4 clusters for the analysis.The code chunk performs the following steps
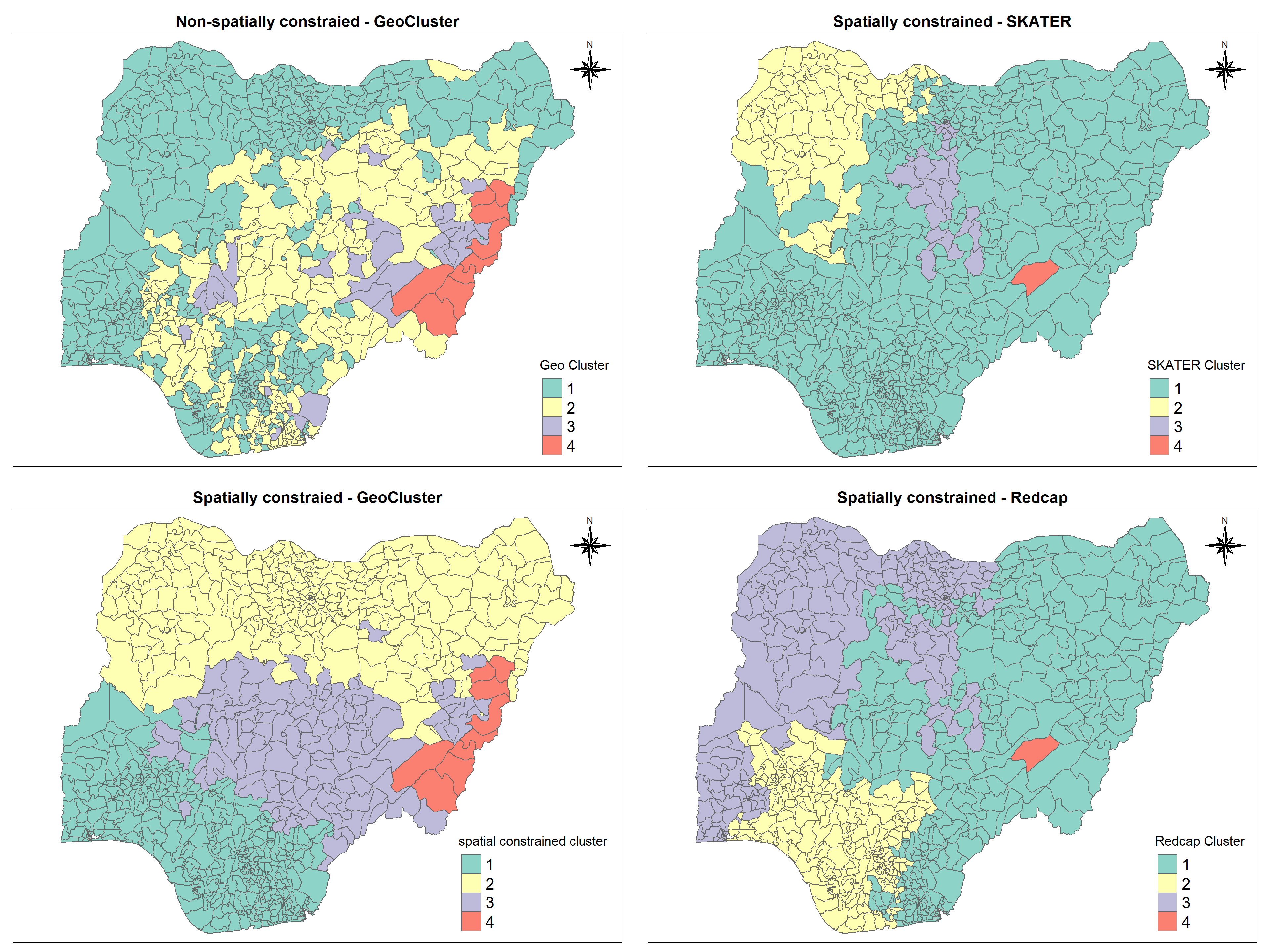
Cluster 1 is predominantly located in the north and western region of Nigeria. Cluster 3 is also spread. It is separated by cluster 2. It leads to difficulty in defining the high-risk cluster and the divisions that belong to this cluster. Cluster 2 occupies the eastern region completely. Although we can see how the clusters are spread across the country, its important for us to understand what constitutes each cluster.
Visual interpretation of clusters - Parallel Plot
To reveal the clustering variables by cluster very effectively, let us create parallel coordinate plot using the code chunk below, ggparcoord() of GGally package
From the above plot, we can infer that the divisions in cluster 1 are majorly urban waterpoints and the staleness of water is very high which is a serious concern. On the other hand, divisions in cluster 4 has higher proportion of functional waterpoints than non-functional waterpoints.
Table 3: Clustering divisions
Cluster
Divisions
Reason
Low Risk - Cluster 4
Bali, Fufore, Ganye, Gashaka, Gombi, Hong
Higher proportion of functional waterpoints than non-functional waterpoints
Medium Risk - Cluster 2
Shomgom,Demsa,Shelleng,Billiri, Kwami, Yola South, Lamurde
Recommended max. users per waterpoint is high
High Risk - Cluster 1
Bursari, Idah, Jos North, Etsako East, Ijebu East
High water staleness
5.9 Spatially Constrained Clustering
In this section, let us perform the following spatially constrained clustering using
Spatial ’K’luster Analysis by Tree Edge Removal (SKATER) method
Spatially Constrained Hierarchical Clustering using ClustGeo method
Spatially constraine clustering using REDCAP method
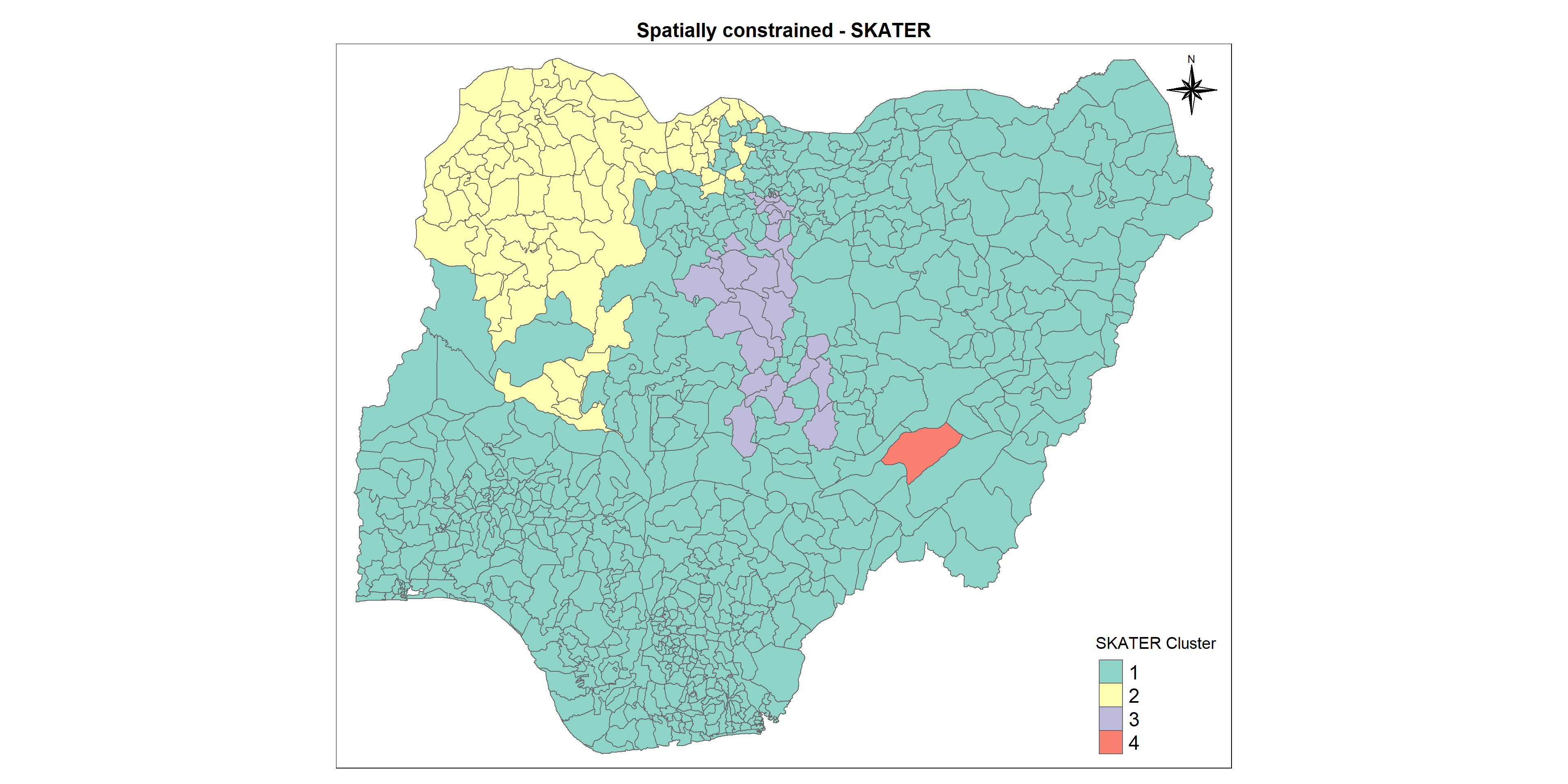
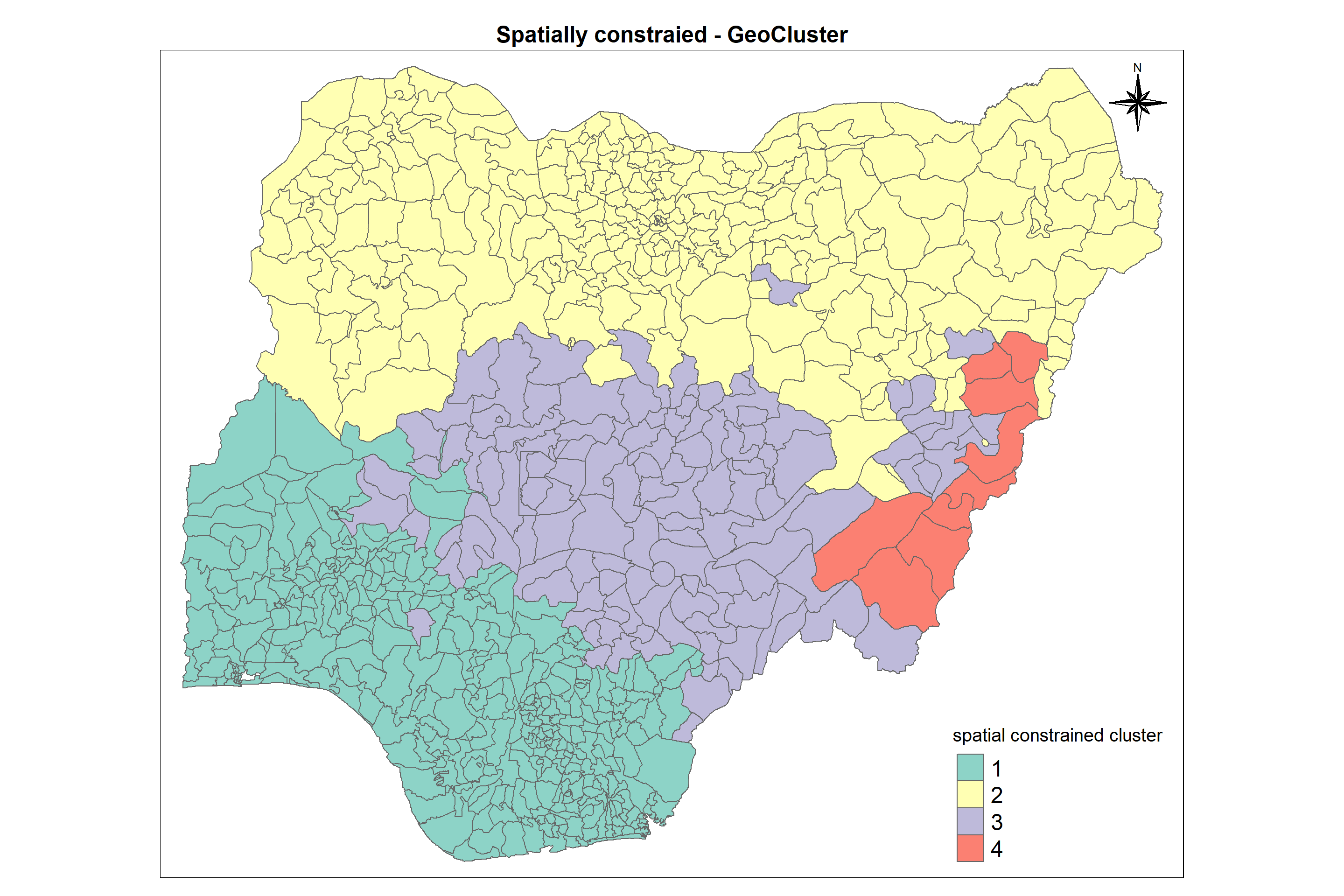
5.9.1 SKATER method
The Spatial C(K)luster Analysis by Tree Edge Removal(SKATER) algorithm introduced by Assuncao et al. (2006) is based on the optimal pruning of a minimum spanning tree that reflects the contiguity structure among the observations. It provides an optimized algorithm to prune to tree into several clusters that their values of selected variables are as similar as possible.
We have to remove the region which has no neighbours while creating a Queen contiguity weight
To reveal the clustering variables by cluster very effectively, let us create parallel coordinate plot using the code chunk below, ggparcoord() of GGally package
Proportion of functional waterpoints is greater than non functional waterpoints in both clusters 1 and 2 which is very good sign and also the percentage of waterpoints with high staleness is lesser in numbers in cluster 2 which is again positive. But the same staleness percentage is quite high in cluster 1 which is a matter of concern.
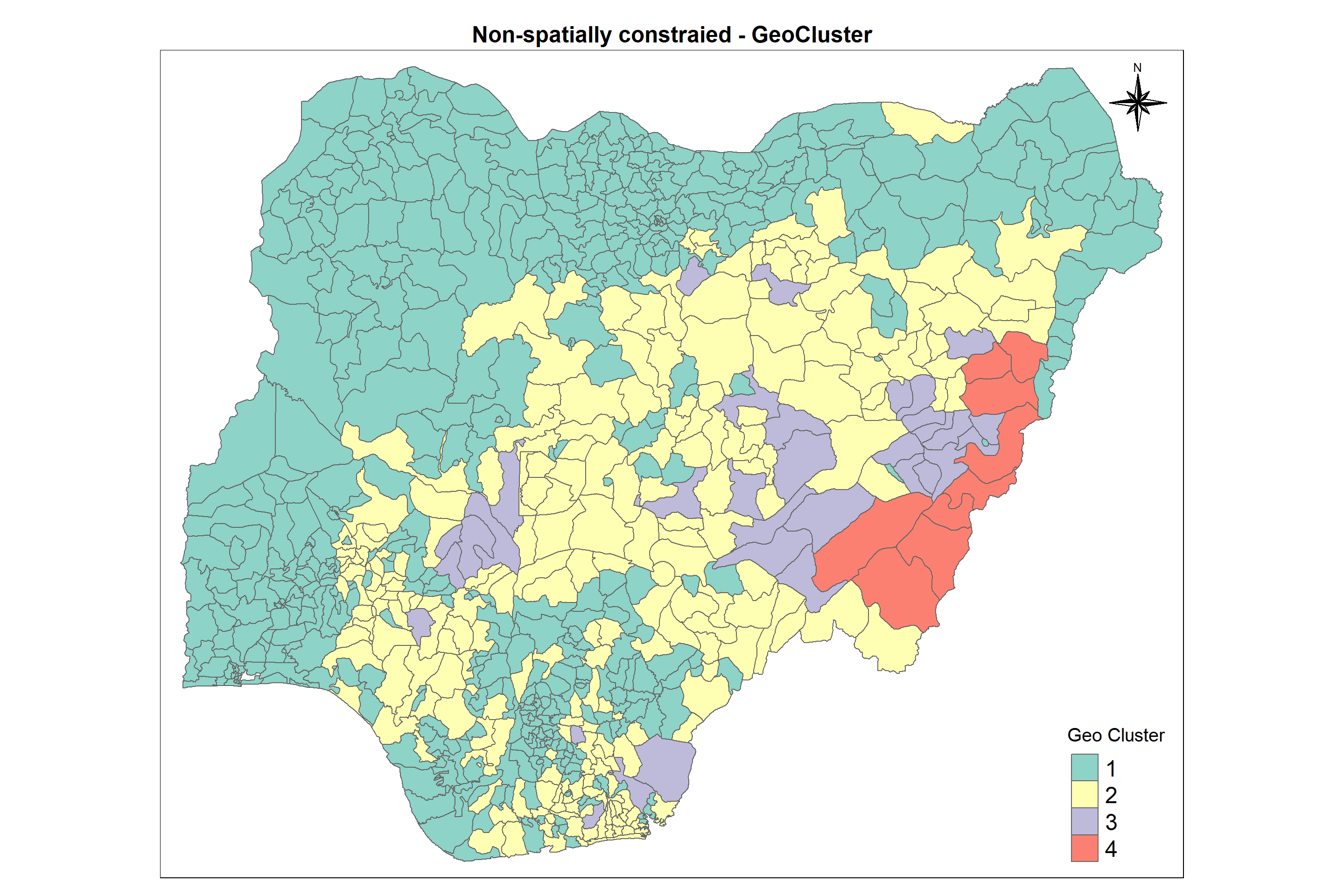
5.9.2 Non spatially constrained clustering using ClustGeo method
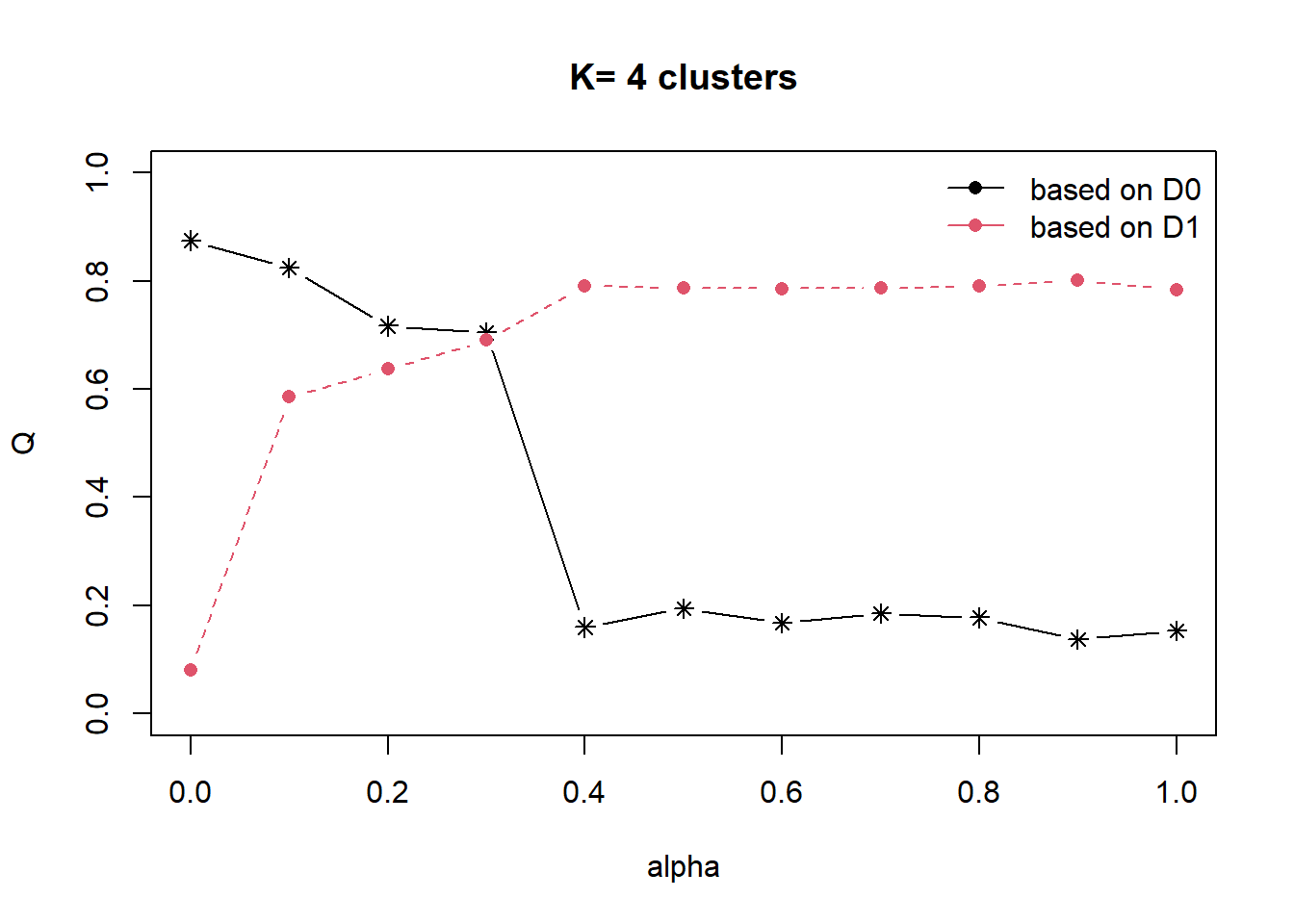
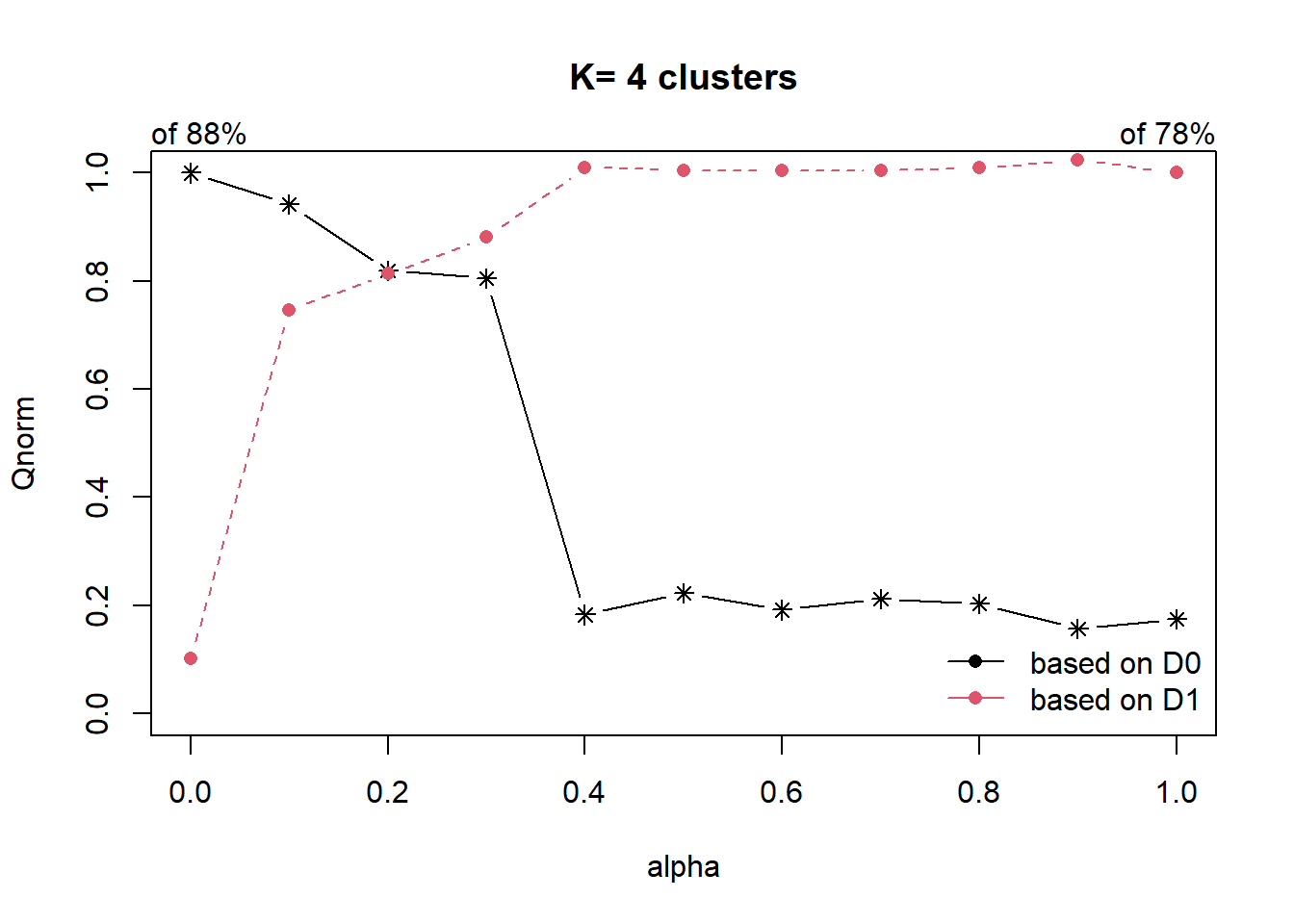
ClustGeo package provides functionalities to perform spatially constrained cluster analysis. This algorithm uses two dissimilarity matrices D0 and D1 along with a mixing parameter alpha, whereby the value of alpha must be a real number between [0, 1]. D0 can be non-Euclidean and the weights of the observations can be non-uniform. It gives the dissimilarities in the attribute/clustering variable space. D1, on the other hand, gives the dissimilarities in the constraint space. The criterion minimised at each stage is a convex combination of the homogeneity criterion calculated with D0 and the homogeneity criterion calculated with D1.
The idea is then to determine a value of alpha which increases the spatial contiguity without deteriorating too much the quality of the solution based on the variables of interest. This need is supported by a function called choicealpha().
The code chunk below compute the spatially constrained cluster using hclustgeo() function of clustgeopackage and perform the join as mentioned in previous section.
To reveal the clustering variables by cluster very effectively, let us create parallel coordinate plot using the code chunk below, ggparcoord() of GGally package
Percentage of functional and non-functional waterpoints is almost the same in both clusters 1 and 2 and whereas proportion of functional points is gretaer than non-functional water points in cluster 4.
5.9.3 Spatially constrained hierarchical clustering using ClustGeo method
Before creating spatially constrained hierarchical clusters, let us perform the following steps
create a spatial distance matrix using st_distance() of sf package
convert the data frame into matrix using as.dist()
determine a suitable value for the mixing parameter alpha using choicealpha()
To reveal the clustering variables by cluster very effectively, let us create parallel coordinate plot using the code chunk below, ggparcoord() of GGally package
From the above multiple parallel coordinate plot, we can infer that most of the waterpoints in cluster 2 are located in urban areas and cluster 3 is at high risk as there are quite a lot of crucial waterpoints but the staleness of water is also high which is a serious concern.
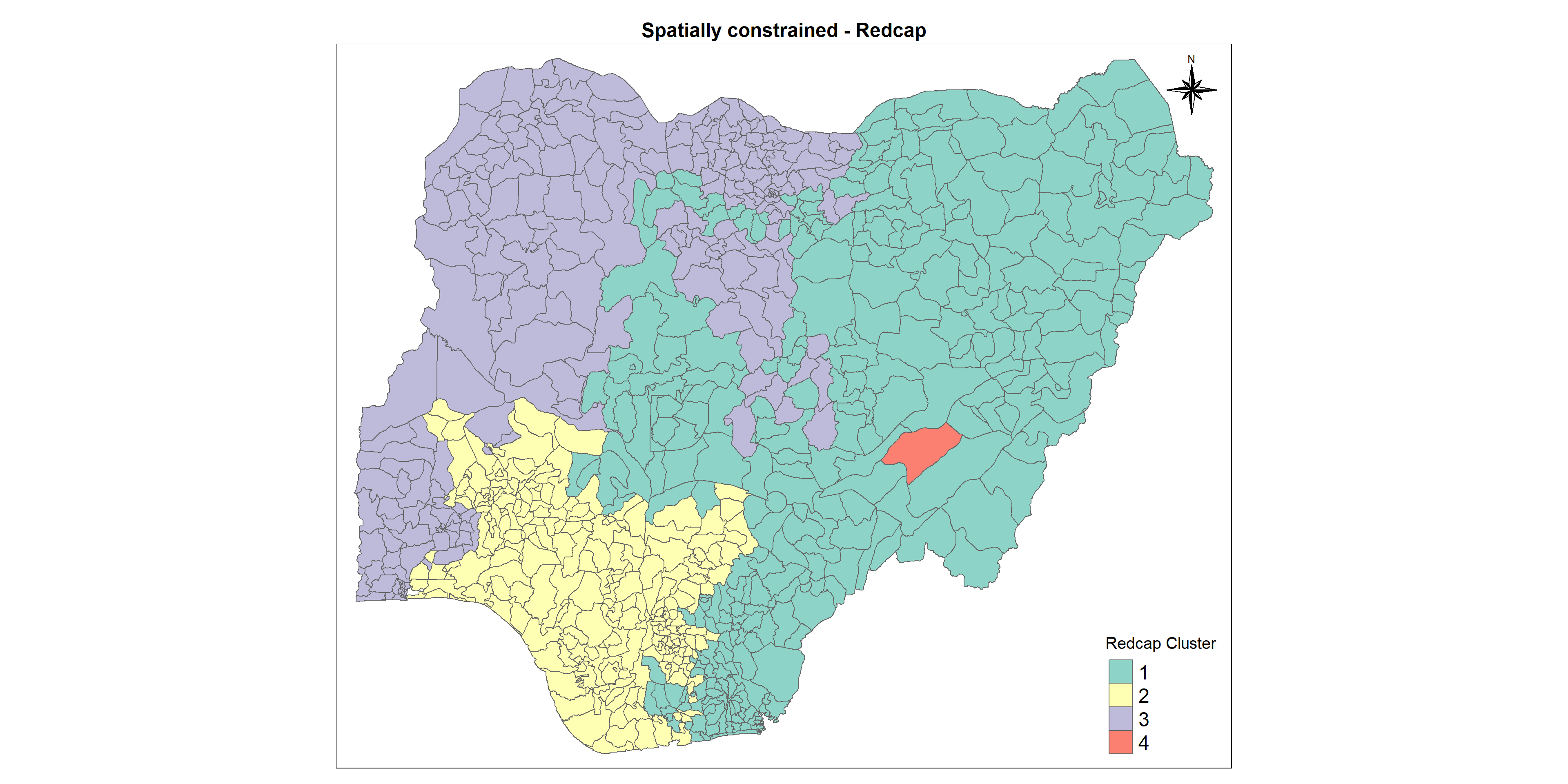
5.9.3 Spatially constrained clustering using REDCAP method
REDCAP (Regionalization with dynamically constrained agglomerative clustering and partitioning) is developed by D. Guo (2008). Like SKATER, REDCAP starts from building a spanning tree in 3 different ways (single-linkage, average-linkage, and the complete-linkage). The single-linkage way leads to build a minimum spanning tree. Then, REDCAP provides 2 different ways (first-order and full-order constraining) to prune the tree to find clusters. The first-order approach with a minimum spanning tree is the same as SKATER. In GeoDa and rgeoda, the following methods are provided:
First-order and Single-linkage
Full-order and Complete-linkage
Full-order and Average-linkage
Full-order and Single-linkage
Full-order and Wards-linkage
The below code chunk is to compute REDCAP clusters with full order complete linkage method using redcap() of rgeoda package.
To reveal the clustering variables by cluster very effectively, let us create parallel coordinate plot using the code chunk below, ggparcoord() of GGally package
It is alarming that in cluster 2 no. of non-functional points is greater than no. of functional points. Also most of the waterpoints here are in urban regions. The cruciality of waterpoints is the same for all the clusters whereas the waterpoints with higher score of staleness (the fact of not being fresh and tasting or smelling unpleasant) are more in cluster 1 and cluster 2 which are to be taken care of.
6. Results & Insights
First, let us plot all the maps together using tmap_arrange() function of tmap package
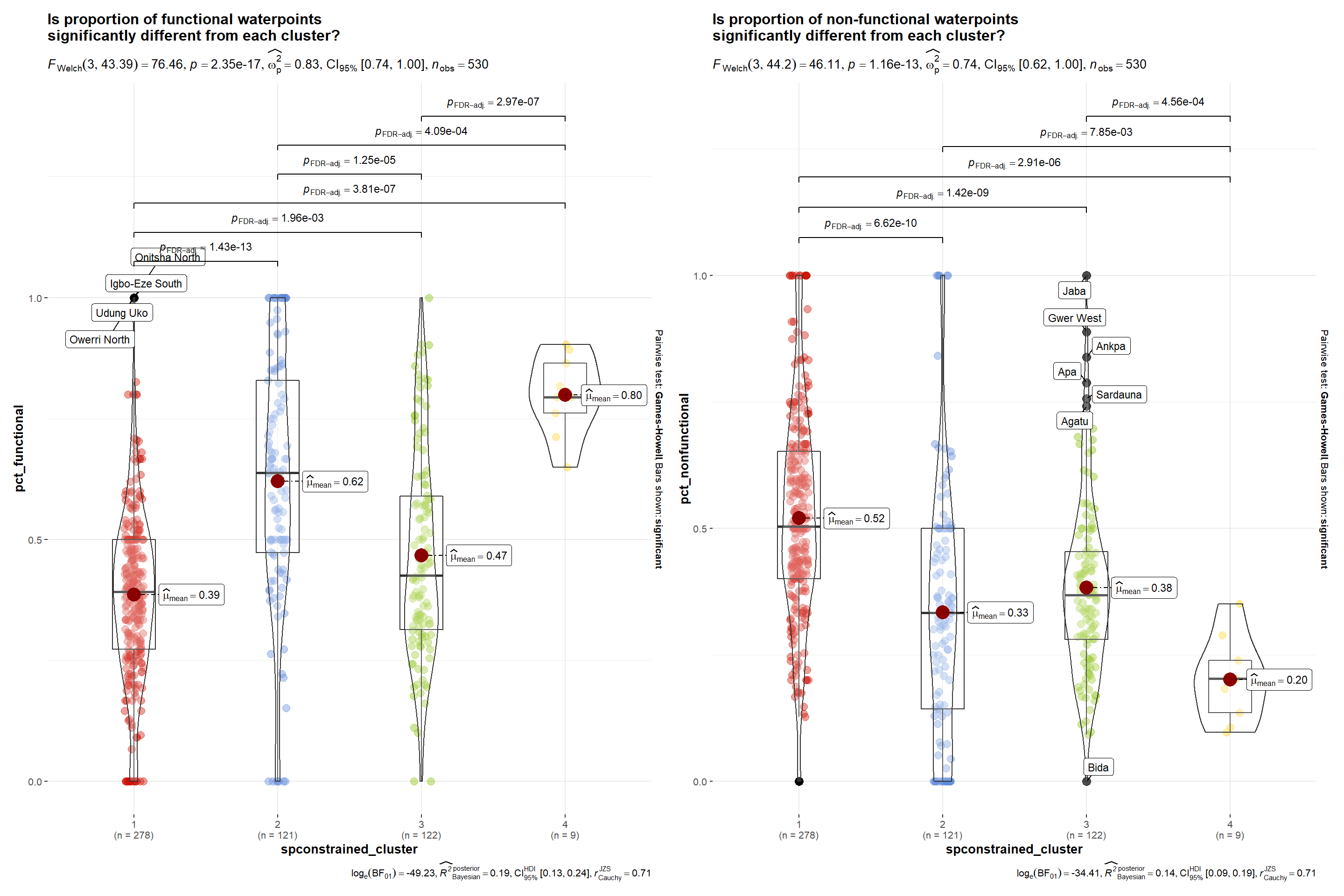
To compare the distributions visually and to check for outliers, let us create statistical plot using ggbetweenstats() of ggstatsplot package.The output is a combination of box and violin plots along with jittered data points for between-subjects designs with statistical details.
Statistical plot
ggp1 <-ggbetweenstats(data = spConstrainedCluster,x = spconstrained_cluster, y = pct_functional,type ="p",mean.ci =TRUE, pairwise.comparisons =TRUE, pairwise.display ="s",p.adjust.method ="fdr",messages =FALSE,title ="Is proportion of functional waterpoints \nsignificantly different from each cluster?",package ="ggsci",palette ="uniform_startrek",outlier.tagging =TRUE, outlier.coef =1.5, outlier.label = shapeName, outlier.label.color ="red", mean.plotting =TRUE, mean.color ="darkblue")ggp2 <-ggbetweenstats(data = spConstrainedCluster,x = spconstrained_cluster, y = pct_nonfunctional,type ="p",mean.ci =TRUE, pairwise.comparisons =TRUE, pairwise.display ="s",p.adjust.method ="fdr",messages =FALSE,title ="Is proportion of non-functional waterpoints \nsignificantly different from each cluster?",package ="ggsci",palette ="uniform_startrek",outlier.tagging =TRUE, outlier.coef =1.5, outlier.label = shapeName, outlier.label.color ="red", mean.plotting =TRUE, mean.color ="darkblue")## combining the individual plots into a single plotcombine_plots(list(ggp1, ggp2))
Given that the p-value of both variables are smaller than 0.05, we reject the null hypothesis, so we reject the hypothesis that all means are equal. Therefore, we can conclude that at least one division is different than the others in terms of percentage of functional and non functional waterpoints. Also from the above plot, it is clear that mean values of percentage of functional and non-functional waterpoints significantly differ from each cluster. Divisions such as Jaba, Dukku, Apa, Sardauna, Gwer West are the outliers in case of percentage of non-functional waterpoints.
Let us tabulate the summary of mean values of each variable across all 4 clusters
Table 4: Mean values of variables across clusters
Variables
Cluster 1
Cluster 2
Cluster 3
Cluster 4
pct_functional
0.2870001
0.2852438
0.4452821
0.7986343
pct_nonunctional
0.3864671
0.1536119
0.3648344
0.2010879
pct_handpump
0.2460482
0.3347766
0.5819492
0.8846085
pct_capmore1000
0.4215695
0.1080063
0.2273853
0.1134975
pct_rural
0.6195961
0.4005031
0.8502495
0.8215736
pct_crucial
0.3570221
0.2167122
0.4115137
0.1512593
pct_stale
0.0696419383
0.0213358622
0.1426163540
0.0002777778
High Risk Divisions (Cluster 1):
The first cluster consists of divisions such as Asa, Bomadi, Ede South, Isu, Kolokuma, Burutu which are all predominantly located at the parts of western and south western Nigeria. The proportion of non-functional waterpoints, usage capacity for people more than 1000, are significantly higher than in any other group of divisions and the handpump proportion, functional waterpoints proportion are significantly lower (results are based on Pairwise Games Howell’s test, One-Way Anova: Post Hoc Multiple Comparison of Clusters). According to those characteristics we name them high risk divisions.
Medium Risk Divisions (Cluster 2 and 3):
The second and third clusters mainly consist of the divisions from the northern and north eastern part of Nigeria namely Kabba, Lokoja, Mikang, Yunusari, Mopa-Muro; some of them are also in the central and south eastern part of Nigeria. In most cases the mean values of variables for those divisions are between the mean values of first and fourth group of divisions. This “second place” is statistically significant for non-functional water points, staleness of waterpoints and the proportion of crucialness. We name them medium risk divisions , since there is one group of division which is less riskier than this group.
Low Risk Divisions (Cluster 4):
Fourth group of divisions are concentrated around Hong, Jada, bali, Fufore, Gashaka, Gombi. So they mainly rural waterpoints in the eastern part of Slovenia which are located at the eastern part of Nigeria. Proportion of non-functional waterpoints, staleness level are lower than in the first and second group and the percentage of functional waterpoints is highest of all groups. Hence, we name them as low risk divisions.
7. Conclusion
In this study, we aimed to explore the results provided by different clustering algorithms in the analysis of delineating homogeneous region of Nigeria by using geographically referenced multivariate waterpoint attributes data. We addressed here both spatial and non-spatial algorithms, allowing us to evaluate and discuss the properties and practical implications inherent to such methods. Incorporating the spatial structure into the analysis led us to more regionalized clusters, with higher spatial cohesion. Identifying high/low-risk spatial cluster of divisions is vital for the remedial steps in future. Ward-like hierarchical clustering algorithm, including spatial constraints using Clustgeo, SKATER, REDCAP algorithms were applied.
de Souza, D. C. & Taconeli, C. A. (2022) “Spatial and non-spatial clustering algorithm in the analysis of Brazilian educational data”, Communications in Statistics: Case Studies, Data Analysis, and Applications. Vol. 8, No. 4, 588-606